目次
辞書の特性について
現在lucene-gosenでは以下の2つの辞書が利用可能です。 簡単に違いについて説明します。
IPAdicの辞書について
- バージョン:2.6.0(※IPAdicとして公開されている最新は2.7.0)
- 最終更新日:2003/06/19
- 登録単語数:約24万語
- NAIST-Jdicができたためか、更新されていない
NAIST-Jdic-for-ChaSenの辞書について
- バージョン:0.4.3(※NAISTとして公開されている最新はMeCab用の辞書0.6.3)
- 最終更新日:2008/07/07
- 登録単語数:約28万語
- IPAdicの後継として整備。品詞の定義など大まかな仕様は共通。
- IPAdicと異なり、アルファベットや数字が1文字ずつ単語として登録されている。
IPAdicとNAIST-Jdicで大きな違いはアルファベットと数字の扱いについてです。 次のような文章をそれぞれの辞書で解析した結果は次のようになります。(SolrのField Analysisの画面です。思いの外大きいのでサムネイルのみですが。) 「このComputerは、10回に1回の割合で起動中に青い画面が表示されます。」 ○IPAdicの場合

○NAIST-Jdicの場合
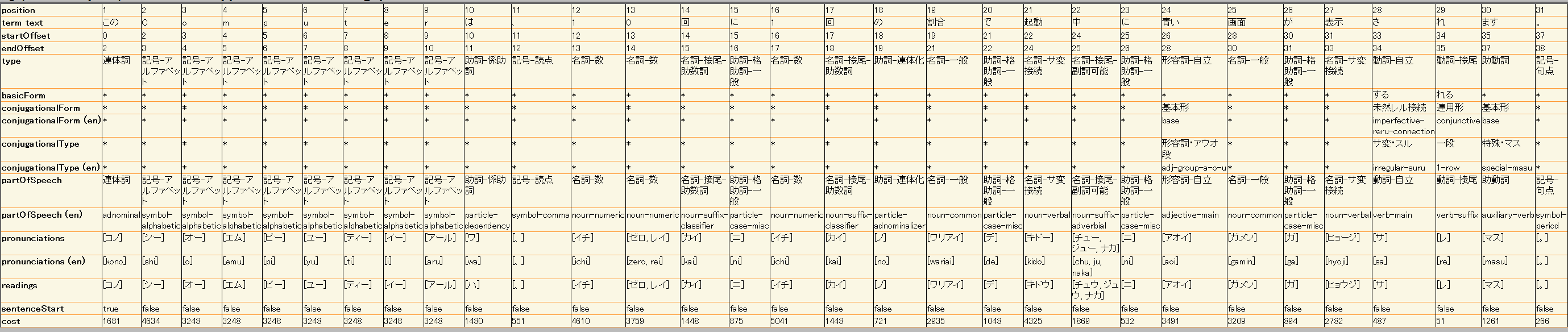
「Computer」と「10」という単語の区切り方が異なることがわかります。 この違いは、辞書のエントリが異なるために発生します。 NAIST-Jdicでは、数字(例:「1」)やアルファベット(例:「a」)が個々のエントリで登録されているため、分割された単語として認識されます。
※この問題への対応方法はまた後日。
カスタム辞書について
実際のデータを形態素解析したい場合、辞書に存在しない単語を登録して、1単語として認識させたい場合があります。(固有名詞など) このような場合にカスタム辞書を利用することで、新しい単語を辞書に登録することが可能になります。 カスタム辞書を利用する手順としては次のようになります。
- カスタム辞書ファイルの作成
- 作成した辞書ファイルを利用したjarファイルの生成
まずは辞書ファイルの作成についてです。 以下では、naist-chasen(NAIST-Jdic)の辞書を例として説明します。(ディレクトリの違いだけで、IPAdicでも同じ方法でOKです。)
lucene-gosenでは辞書のコンパイルに2つのフェーズが存在します。
- gosen用辞書を生成する前処理(中間csvファイルの生成)
- gosen用バイナリ辞書の生成
カスタム辞書は1の出力の形式(=中間csvファイル=dictionary.csv)にあわせたCSVファイルとして作成します。 CSVの各カラムは次のような意味を持っています。
| 単語 | 単語の生起コスト | 品詞 | 品詞細分類1 | 品詞細分類2 | 品詞細分類3 | 活用型 | 活用形 | 基本形 | 読み | 発音 |
**"達川",2245,名詞,固有名詞,人名,名,*,*,"達川","タツカワ","タツカワ"**
上記ファイルを、先日紹介した$LUCENE-GOSEN/dictionary/ディレクトリにコピーします。 では、カスタム辞書を含んだlucene-gosenのjarを作成しましょう。 カスタム辞書のビルドは$LUCENE-GOSEN/dictionary/で行います。 また、カスタム辞書の指定はCSVファイル名をantの引数で指定します。次がコマンドの例になります。
$ cd lucene-gosen-trunk
$ cd dictionary
$ ant -Ddictype=naist-chasen clean-sen
$ ant -Ddictype=naist-chasen -Dcustom.dics="../custom-dic.csv" compile
$ cd ..
$ ant -Ddictype=naist-chasen
上記コマンドの例で"clean-sen"というタスクを実行しています。これは、すでに出来上がっているgosen用のバイナリ辞書を削除するタスクになります。すでにgosen用の辞書が作成されている場合には辞書の再生成が行われないためです。 また、複数のファイルを利用したい場合は-Dcustom.dics=“custom-dic.csv custom-dic2.csv"という形でスペース区切りでファイル名を記述すればOKです。
カスタム辞書を適用する前と適用後の違いは次のとおりです。 適用前
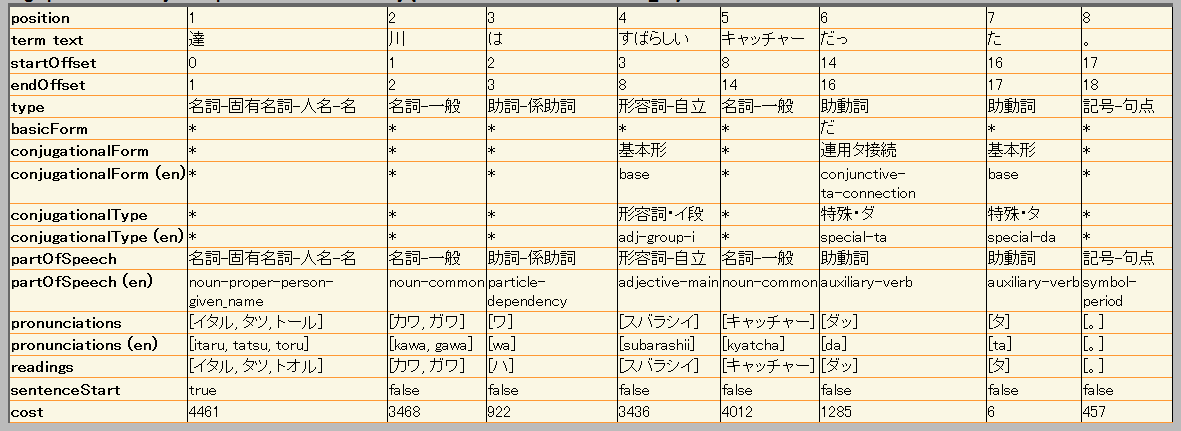
適用後

簡単ですが、以上がカスタマイズ辞書を利用する方法でした。 ちなみに、この記事を書く前にすでにカスタム辞書の件を書いているブログがありました。。。こちらも参考にしてください。 今回の例でいくつかSolrのanalysis画面を利用して説明してきました。Solrでのlucene-gosenの利用方法についてはまた後日記載したいと思います。 ※参考までに。Solrでの利用方法はこちらにも記載してあります。
また、IPAdicなどの辞書について記載のある書籍を見つけましたので、参考になれば。

comments powered by Disqus
See Also by Hugo
- NAIST-JDic for MeCab対応版(仮実装)(Jugemより移植)
- 辞書の外部化とLucene/Solr3.4対応(Jugemより移植)
- 辞書のjarファイルからの分離(Jugemより移植)
- lucene-gosenのUniDic対応(Jugemより移植)
- lucene-gosenとSynonymFilterを利用するときの注意点(問題点編)(Jugemより移植)
