目次
今日は、ElasticSearchのMLで見つけたelasticsearch-inquisitorプラグインの紹介です。
ElasticSearchはREST API形式で簡単にコマンドラインからいろいろな処理を実行できて便利ですが、 GUIがあったほうが楽なこともまた事実です。 今回紹介する、inquisitorプラグインもSiteプラグイン(Webブラウザでアクセスできるプラグイン)の1つです。 (ただし、ローカルにインストールしてローカルのElasticSearchにしか接続できませんが。。。)
インストール
プラグインですので、以下のコマンドでインストールが出来ます。インストール後はElasticSearchの再起動が必要です。
bin/plugin -install polyfractal/elasticsearch-inquisitor
ElasticSearch再起動後に、以下のURLにアクセスすればOKです。 ※ローカルでのみ動作可能なプラグインです。(内部で呼び出しているJSにlocalhostと記載があるため)
http://localhost:9200/_plugin/inquisitor/#/
何ができるの?
自分の書いたQueryが正しく動作するかや、Analyzerによって文章がどのように、Term(Token)に分割されるかといった挙動をWebブラウザ上で確認することができます。用意されている画面は「Queries」「Analyzers」「Tokenizers」の3種類です。
Queries
クエリの確認、実行が可能な画面です。
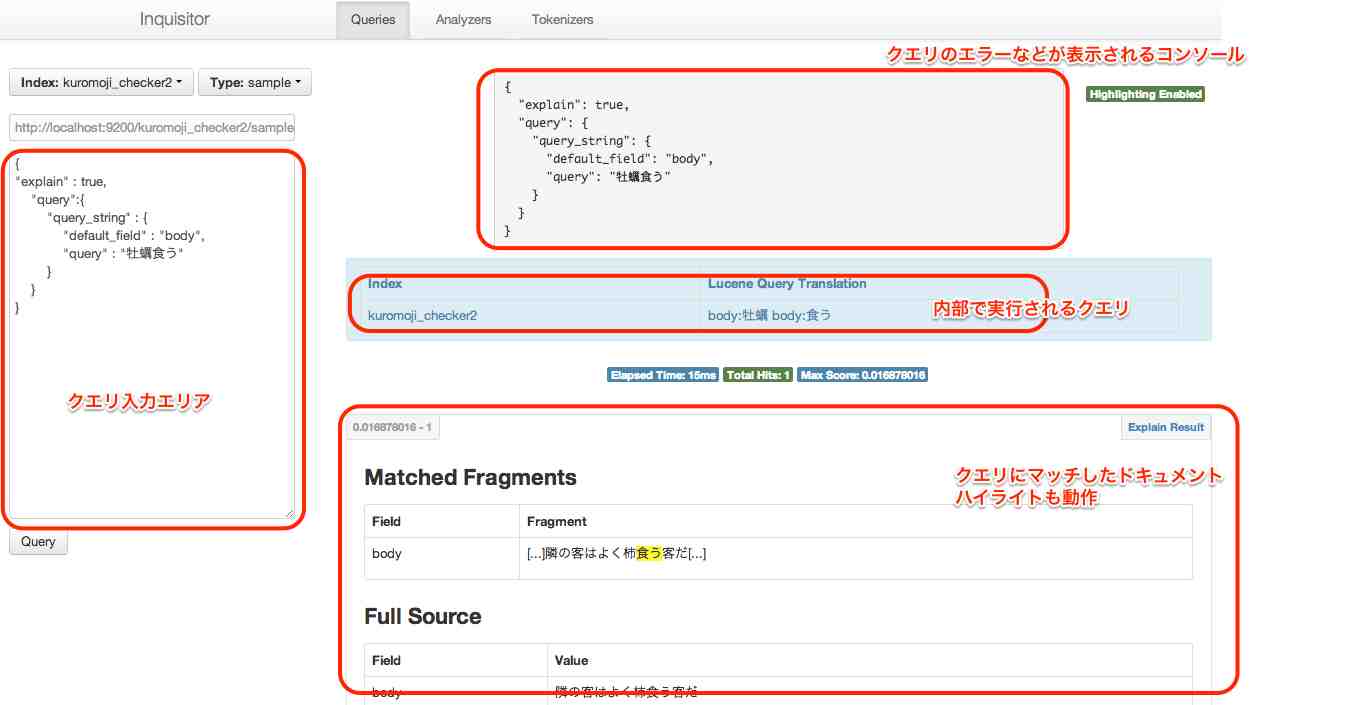
「Index」「Type」はプルダウンになっており、現在ElasticSearchに存在しているものが選択可能です。 その下のテキストエリアがクエリを入力する画面です。
クエリを入力していると、入力しているクエリがValidかどうかをクエリのコンソール部分(右側上部)に表示してくれます。

少し残念なことに、Tabを押すと、フォームのフォーカスが切り替わってしまうので、クエリを入力するのがちょっと面倒です。。。(私は通常の検索には、ChromeプラグインのSenseというものを利用してます。)
クエリに問題がない場合は、「Query」ボタンを押すことで実際の検索が実行されます。 この時、画面真ん中のブルーのテーブル(内部で実行されるクエリ)の部分に、QueryがElasticSearch内部で解釈されたあとの、Luceneで実行されるレベルのクエリに変換されたクエリが表示されます。
これが便利です。JSONで記述したり、色々なタイプのクエリがElasticSearchでは実行できますが、望んだ形に単語が区切られているかなどを確認することができるため、非常に便利です。
ElasticSearchのQuery DSLではexplainをtrueにすることで、ヒットしたドキュメントのスコア計算に用いられた単語などがわかるのですが、そもそもヒットしないクエリの場合は、explainでは単語の区切られ方などがわかりません。
その場合に、このプラグインで確認すると、想定と違う単語の区切られ方やクエリの造られ方がわかるかと思います。
Analyzers
Analyzerによる文章のアナライズ結果の確認が出来る画面です。 ElasticSearchやSolrにあまり詳しくない場合、どんなAnalyzerが文章をどのように単語に区切って、転置インデックスのキーワードとして利用しているかがわからないと思います。
このAnalyzerが文章をどのように単語に区切っているかを確認することができるのがAnalyzers画面です。 こんなかんじの画面になります。
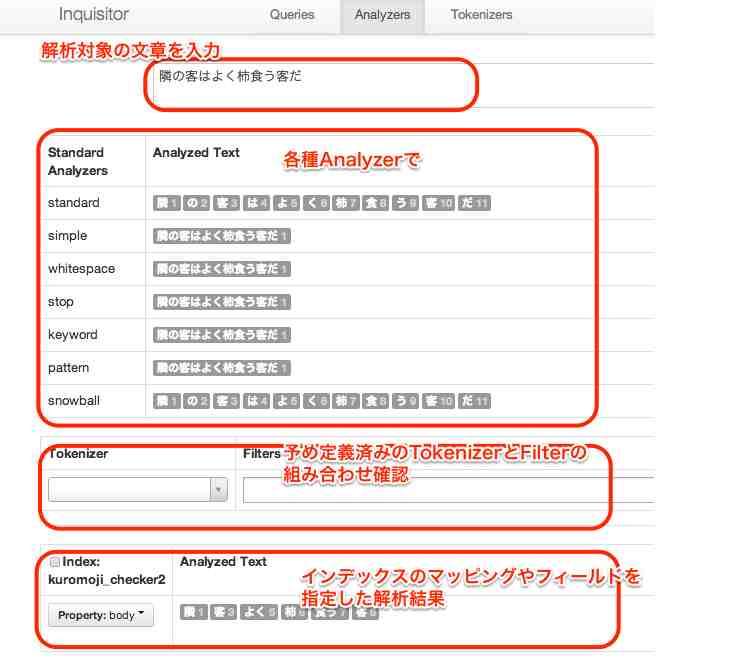
一番上のテキストエリアが文章を入力する場所です。 文章を入力していくと、その下のテーブルの「Analyzed Text」の部分が変化していくのが分かります。 このグレーの単語が転置インデックスのキーワードとなります。
予め用意されているAnalyzer以外に、用意されているTokenzier+Filterの組み合わせも簡単ですが確認可能です。(Tokenizer、Filtersとあるテーブル) ただし、ここまでのどちらも細かな設定は画面上ではできません(Filterの細かな引数の指定など)
一番下の部分が、ElasticSearchに存在しているインデックスごとに定義されたAnalyzerやフィールドを元にした解析結果を表示することができる領域です。
自分でマッピングを記述してフィールド定義したものの動作確認や、インデックスを適当に作ったけど、うまくヒットしない場合など、ここで、単語の区切れ方を確認することで、検索になぜヒットしないのかといった問題のヒントを得ることができると思います。
Analyzerによっては、インデックス対象の文字として扱わない文字があったりしますので。 先ほどのQueries画面のLuceneに投げられる直前のクエリと、Analyzersでの単語の区切られ方を確認することで、検索がうまくヒットしていないことが判明すると思います。
Tokenizers
最後はTokenizers画面です。Analyzersとほぼ同様ですが、ちがいは、デフォルトで用意されているTokenizerの挙動の確認ができるというだけになります。
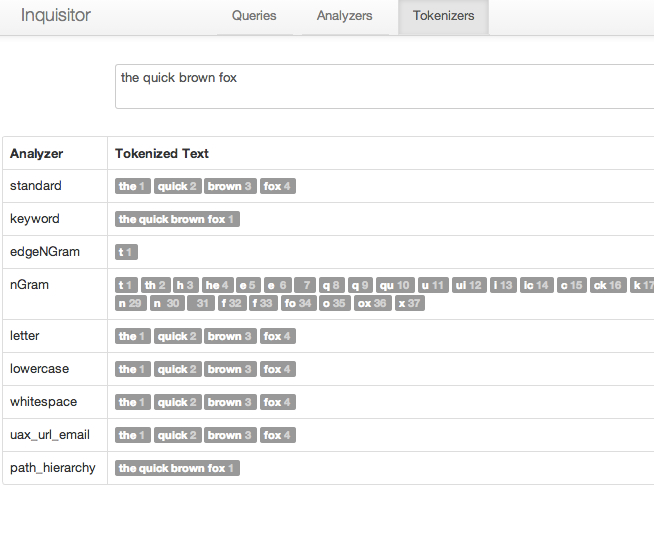
簡単な確認ならここで可能かと。
注意点は?
まだ開発途中のようで、つぎの部分が課題かと。
- ローカルでのみ実行可能
- Queries画面の結果の「Explain Result」リンクが未実装
- Queries画面のクエリ入力が使いにくい(タブが打てないので)
- カスタム登録のAnalyzersはインデックスを用意しないと確認できない。(Kuromojiのプラグインを登録しただけでは確認できなかった)
- 細かな設定のフィールドも用意しないと、Analyzers画面では利用できない
まとめ
ということで、Inquisitor(読みがわからない)プラグインの簡単な説明でした。 検索にうまくヒットしないという理由は大体の場合、 クエリに入力した文字列が単語に区切られたものと、登録したデータが単語に区切られたものが異なるために検索にヒットしないというものです。
そのクエリ、データの単語の区切られ方を確認するのに役に立つプラグインじゃないでしょうか。
ちなみに、このプラグイン自体はHTML+JSで作成されており、実際にはElasticSearchが持っているREST APIをキックしているだけになります。 ですので、Web画面なんか要らないという方は、このプラグインが実際に送信しているリクエストを参考にするとcurlコマンドでどういったリクエストを投げればいいかというのがわかると思います。
私は軟弱者なので画面があったほうがいいですが。
comments powered by Disqus
See Also by Hugo
- Querqyの調査(その1)
- ElasticsearchのAnalyze APIのVisual Studio Codeのクライアントプラグイン
- Lucene Kuromoji for NEologdで指定した品詞の単語を抜き出すIngest Pluginを書いてみた #elasticsearchjp
- Elasticsearch 2.0.0リリース(日本語訳)
- プロキシ環境でのpluginコマンドの実行
