目次
お久しぶりです。 気づいたらまた、結構ブログを書いてなかったです。。。
今回は、今開発しているElasticsearchのプラグインに関するお話です。
いやぁ、名前決めるの難しいですね。これで英語的に合ってるか不安ですが、elasticsearch-extended-analyzeというプラグインを作っています。
どんなもの?
Solrの管理画面のanalysisに相当する機能が欲しくて作り始めました。
Elasticsearchにはanalyze APIというAPI(名前あってるのかなぁ?)が存在します。
これは、文字列を投げると、指定したアナライザやトークナイザでどのようなトークンに分割されるかを調べることができるAPIです。
例えば、elasticsearch-analysis-kuromojiをインストールしたElasticsearchに対して、以下のcurlコマンドを実行します。
curl -XPOST 'localhost:9200/_analyze?tokenizer=kuromoji_tokenizer&filters=kuromoji_baseform&pretty' -d '寿司が美味しい'
すると、トークナイズされた結果が次のようなJSONで返ってきます。
{
"tokens" : [ {
"token" : "寿司",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
}, {
"token" : "が",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 2
}, {
"token" : "美味しい",
"start_offset" : 3,
"end_offset" : 7,
"type" : "word",
"position" : 3
} ]
}
トークナイズの結果がわかるのは嬉しいのですが、どんな品詞なのかといったKuromoji固有のTokenの属性情報がなくなってしまいます。
Solrでは、こんな画面が用意されていて、品詞情報とかが出力されます。あとは、各TokenFilterでどのトークンがなくなっているかなどもわかるようになっています。
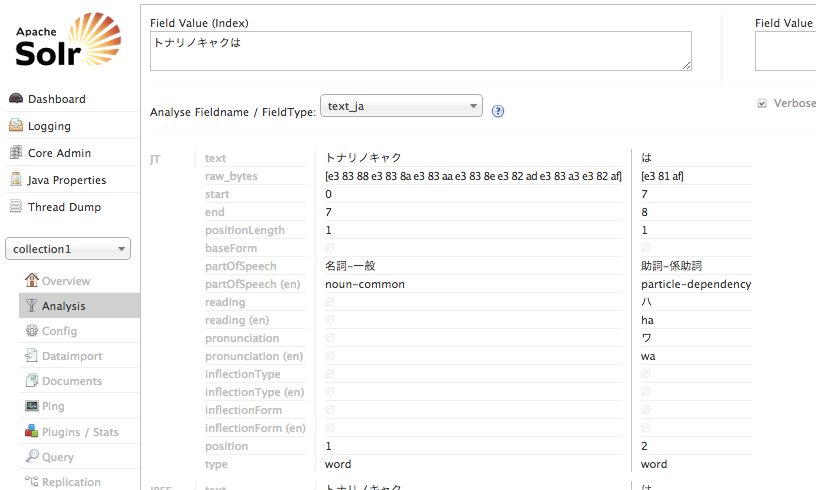
これって結構役立つと思うんですよ。 ということで、Pluginも作ってみたかったので、いい機会だから作ってみようかと。
出力サンプル
まずは、その他のAttribute(品詞とか)を表示するところを実装してみました。
curl -XPOST 'localhost:9200/_extended_analyze?tokenizer=kuromoji_tokenizer&filters=kuromoji_baseform&pretty' -d '寿司が美味しい'
先ほどとほぼ一緒のcurlコマンドを実行します。違う点は**「_analyze」が「_extended_analyze」**となっている点です。
で、実行結果はこんな感じです。(長いですがそのまま載せてます。続きの文章がしたにあります。)
{
"tokens" : [ {
"token" : "寿司",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1,
"extended_attributes" : [ {
"org.apache.lucene.analysis.tokenattributes.TermToBytesRefAttribute#bytes" : "[e5 af bf e5 8f b8]"
}, {
"org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute#positionLength" : 1
}, {
"org.apache.lucene.analysis.ja.tokenattributes.BaseFormAttribute#baseForm" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech" : "名詞-一般"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech (en)" : "noun-common"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading" : "スシ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading (en)" : "sushi"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation" : "スシ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation (en)" : "sushi"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType (en)" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm (en)" : null
}, {
"org.apache.lucene.analysis.tokenattributes.KeywordAttribute#keyword" : false
} ]
}, {
"token" : "が",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 2,
"extended_attributes" : [ {
"org.apache.lucene.analysis.tokenattributes.TermToBytesRefAttribute#bytes" : "[e3 81 8c]"
}, {
"org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute#positionLength" : 1
}, {
"org.apache.lucene.analysis.ja.tokenattributes.BaseFormAttribute#baseForm" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech" : "助詞-格助詞-一般"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech (en)" : "particle-case-misc"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading" : "ガ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading (en)" : "ga"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation" : "ガ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation (en)" : "ga"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType (en)" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm (en)" : null
}, {
"org.apache.lucene.analysis.tokenattributes.KeywordAttribute#keyword" : false
} ]
}, {
"token" : "美味しい",
"start_offset" : 3,
"end_offset" : 7,
"type" : "word",
"position" : 3,
"extended_attributes" : [ {
"org.apache.lucene.analysis.tokenattributes.TermToBytesRefAttribute#bytes" : "[e7 be 8e e5 91 b3 e3 81 97 e3 81 84]"
}, {
"org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute#positionLength" : 1
}, {
"org.apache.lucene.analysis.ja.tokenattributes.BaseFormAttribute#baseForm" : null
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech" : "形容詞-自立"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.PartOfSpeechAttribute#partOfSpeech (en)" : "adjective-main"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading" : "オイシイ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#reading (en)" : "oishii"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation" : "オイシイ"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.ReadingAttribute#pronunciation (en)" : "oishii"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType" : "形容詞・イ段"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionType (en)" : "adj-group-i"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm" : "基本形"
}, {
"org.apache.lucene.analysis.ja.tokenattributes.InflectionAttribute#inflectionForm (en)" : "base"
}, {
"org.apache.lucene.analysis.tokenattributes.KeywordAttribute#keyword" : false
} ]
} ]
}
先ほどの結果に**「extended_attributes」**という配列のオブジェクトが追加された形になっています。 ちょっと長くなってしまいましたが。。。
Solrの処理を真似して作ったので大したことはやってないんですが、少しは便利になるかもなぁと。
現時点では、最終的な結果しか取得できないですが、今後は次のような機能を作っていこうかと思っています。 できるかどうかは、やってみてって感じですが。
- pluginコマンドでインストール
- pom.xmlはありますが、まだMavenとかに登録はされていません。ですので、
mvn packageしてからjarファイルをpluginsフォルダに配置しないといけません。pluginコマンドでインストールできるともっと使ってもらえるはず?
- pom.xmlはありますが、まだMavenとかに登録はされていません。ですので、
- 出力したいAttributeの指定
- リクエストパラメータで、出力したいAttribute名を指定するとか。
- 出力形式の変更
- 今は、Solrの真似をしていますが、せっかくJSONだったりするので、もう少し検討しようかと(同じAttributeの異なる値も1オブジェクトとして出力されてる)
- TokenizeChainの出力
- Solr同様、CharFilter、Tokenizer、TokenFilterが動作して、最終的なTokenがインデックスに登録されます。ですので、各処理の直後のTokenがどうなっているかもわかったほうが嬉しいと思うので、それらも取得できるようにしたいなぁと
- 画面の用意
- せっかくプラグインなんだし、画面で見れると嬉しいかなと。これは当分先になっちゃうと思いますが、Webページで確認できるような画面を作ると確認しやすくなるかなぁと。上記対応が終わってから取替かかると思いますが。
とりあえず、思いつくのはこんなかんじです。
Elasticsearchの_analyze APIを真似しただけのコードだし、テストも実装もまだまだですが、とりあえず公開してみました。
要望などあれば、コメント、Issue、ツイート(もちろん、テストコードなども!)なんでも受け付けてますので、お気軽に。
comments powered by Disqus
See Also by Hugo
- elasticsearch-extended-analyzeの改良
- いつも入れているElasticsearchのプラグイン
- elasticsearch-kopfの紹介(aliases画面)
- stream2esと複数データの登録
- elasticsearch-kopfの紹介(analysis画面)
