目次
luceneutil - マニアックなツールのセットアップの続きです。 今回も誰得?なブログなので興味ない場合は飛ばしましょう。
一応、luceneutilのREADMEにあるlocalrun.pyを動かせるところまでいったんですが、そこで一旦本題を思い返してみました。
Kuromojiの性能が落ちてるらしいし、Analyzer系のベンチマーク測ってるグラフに載せたほうがいいよね。
これが、そもそも動かしてみようと思った本題です。 READMEに書いてある手順で動いたんですが、よくよく調べてみると、Analyzer系の性能テストをやってるのは、別物っぽいぞと。 なんとなく、「ソフトウェア考古学」っぽくなってきましたね。
Analyzerの性能テストやってるのは?
Analyzerのパフォーマンステストのグラフに出てきたTokenizerの名前を元にluceneutilのリポジトリを検索してみました。
EgdeNGrams当たりで検索するとヒットしたのが以下のファイルです。
src/main/perf/TestAnalyzerPerf.javasrc/main/perf/TestAnalyzerPerf4x.javasrc/python/sumAnalyzerPerf.py
本命はsrc/main/perf/TestAnalyzerPerf.javaっぽいですね。
これを動かしている人はどれかな?ということで、今度はこのファイル名で検索します。
どうやら、このPythonのファイルが先程のJavaファイルを実行して、性能を計測しているみたいです。
最初に出てきた、sumAnalyzerPerf.pyはrunAnalyzerPerf.pyの実行結果をAnalyzerの計測結果のグラフに追加する処理をしているようだということまでがわかりました。
KuromojiをTestAnalyzerPerfに追加してみる
動かす対象がわかったので、あとは、やることを追加しましょうと。
- Kuromojiの実行を
TestAnalyzerPerfに追加- 引数を追加して日本語版のWikipediaのファイルも読み込むようにする
runAnalyzerPerf.pyに引数の追加とクラスパスの追加- JapaneseAnalyzerは
lucene/analysis/kuromojiにビルドされるのでクラスパスを追加 - 引数に日本語版のWikipediaのファイルを追加
- JapaneseAnalyzerは
- 日本語版のWikipediaのデータの用意
こんなものかな?と。
1と2はそれほど大変ではないので、3をまずはというところから始めてみました。
WikipediaのXMLから1行1データのTSVファイルに
まずは、どんなファイルを想定して動いているのかな?ということで、英語版のファイルがどんなものかを探してみることに。
TestAnalyzerPerf.java (77行目)では入力ファイルから1行ずつ文字列を読み込んでAnalyzerに処理させているだけというのがわかっています。なので、とりあえず、1行ずつ読めるような形式だと。
次に、runAnalyzerPerf.pyの55行目でenwiki-20130102-lines.txtというものを読み込んでいます。
が、これがよくわからないw
前回とりあえず動いたときに、src/python/constants.pyにいろんなファイルへのパスとかが記載されていたのを覚えていたので、その当たりから調べてみます。
52行目に約665万件のドキュメントだというような記載があります。
前回のlocalrun.pyのファイルと似たような構造(1行に1記事が埋め込まれたTSVファイル)だろうと判断して、それを作りそうなプログラムを探してみました。
Wikiとかで検索して見つけたのがこのソースたちでした。
src/python/wikiXMLToText.py- それっぽい名前ですよね?- 中身を見ると、第1引数のファイル(XML)から
pageタグごとにデータを抜き出し、処理をしてからタブ区切りで第2引数のファイルに書き出してます。
- 中身を見ると、第1引数のファイル(XML)から
src/python/WikipediaExtractor.py- これもそれっぽいですね。WikipediaExtractory.pyは界隈では有名なhttps://github.com/attardi/wikiextractorみたいです。こっちはなんとなく使い方はわかっています。
src/python/combineWikiFiles.py- これまたそれっぽい。- 中身を見ると、1番目のコードで出力したデータに、2番めのコードで出力されたデータを元になにかしら処理をして、引数で与えられたファイルに出力する感じになってます。
ということで、完全に憶測ですが、日本語のWikipediaのXMLファイルを元に次のような流れでファイル作ってみればいいのかな?と。
jawiki-20200620-pages-articles.xml.bz2をwikimediaからダウンロードして、unbzip2で展開python src/python/wikiXMLToText.py jawiki-20200620-pages-articles.xml jawiki-lines.txtで、1行ごとのデータを作る- ちなみに、このプログラムは2箇所ほど修正しました。
usernameタグが存在しないpageが出力されなさそうなので、デフォルトでusername: ""みたいなデータをattrってディクショナリに設定しました。
- ちなみに、このプログラムは2箇所ほど修正しました。
cat jawiki-20200620-pages-articles.xml | python -u src/python/WikipediaExtractor.py -b102400m -o extractedで別途XMLからデータを抽出python src/python/combineWikiFiles.py jawiki-lines.txt extracted/AA/wiki_00 jawiki-20200620-lines.txtで2と3の出力をかけ合わせる
で、まぁ、一応ファイルはできたんですが。。。
前回のブログ記事でセットアップしたときにダウンロードされたファイルはtitle、日付、本文の3つのカラムしかないんですが、上記の手順で作り出したファイルにはいろんなカラムが存在するんですよね(2が出力する項目が結構ある)。。。
性能テスト用プログラムの書き換え
入力ファイルは出来上がったので、あとは、性能テストを走らせる部分の修正です。 修正部分はプルリク見たほうが明確なので省略で。
実行してみた
で、実行してみました。
せっかくなので、ブランチをbranch_8_5とmasterを対象にしてやってみました。
実際にはsrc/python/runAnalyzerPerf.pyにディレクトリ名やブランチ名が直書きされてたので書き換えつつ実施した結果はこちら。
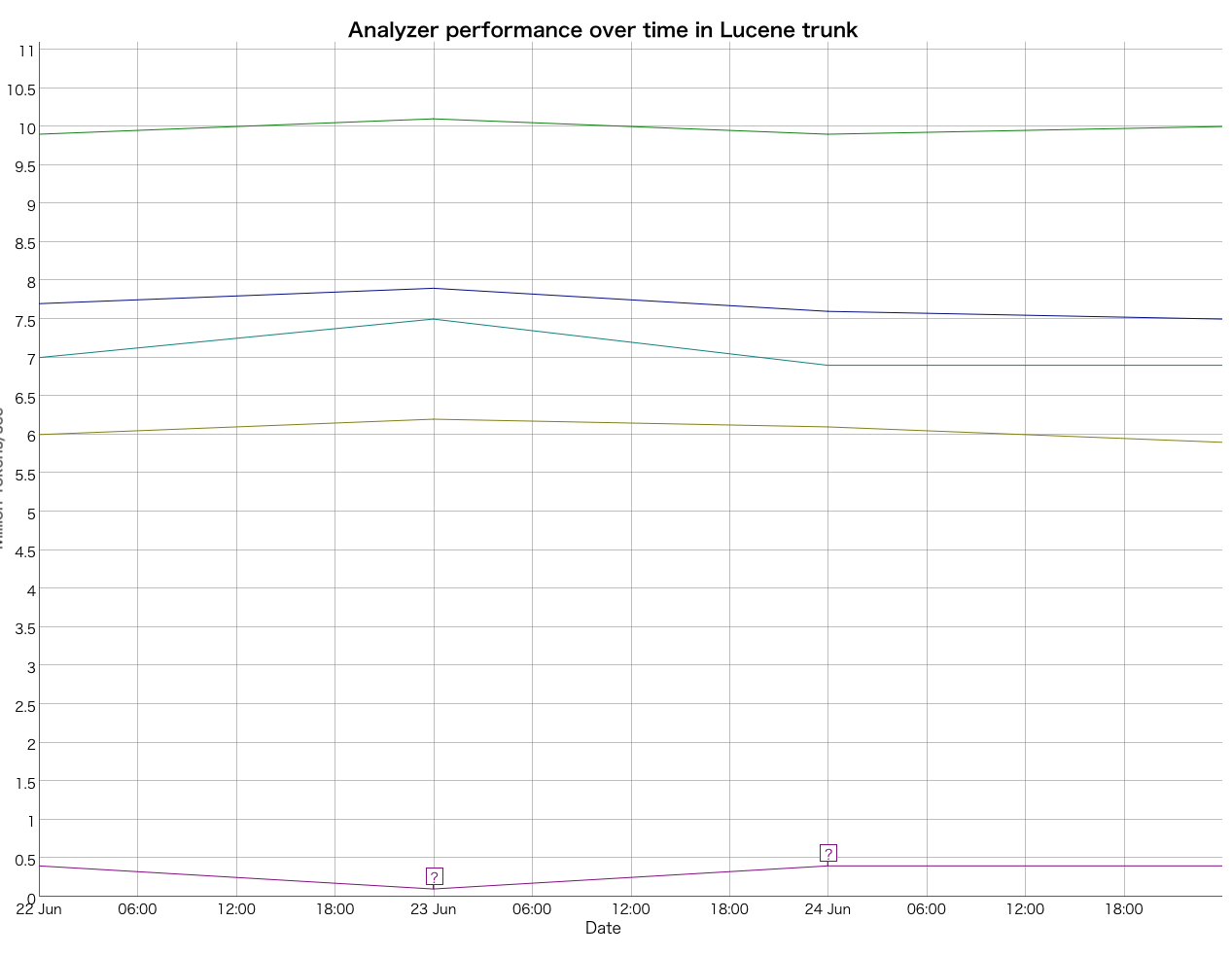
他の英語系のAnalyzerと同じグラフに載せてみたのですが、遅いので、下の方に表示されてます。
で、下に凹んだ部分(23 Juneのところ)がbranch_8_5で実行したときの性能値でした。
実際に遅くなってますね。ただ、他のAnalyzerの振れ幅も大きいので、別のグラフにしたほうがわかりやすくなるのかもなぁと思った次第です。
ということで、一応動いたんでプルリク出してみました。 採用されるかなぁ?
一応誰得ブログはこれでおしまい。 Noriとかもこの感じで対応できるんじゃないかな?
comments powered by Disqus
