目次
本記事は情報検索・検索技術 Advent Calendar 2022の9日目の記事です。
だいぶ間が空いてしまいましたが、日本語のオートコンプリートに関する記事の続きです。 という感じで、Suggesterのデータ構造とか仕組みを書こうと思っていたのですが、思ったよりも調べないといけないことが多くて挫折しました。。。 (これの続きは年末年始で調べて書くはず?)
ということで、代わりにElasticsearch/OpenSearchのアーキテクチャの変更に関してさらっとまとめてお茶を濁してみようと思います。
発端はElasticON Tokyo?
先週の11月30日に、ElasticのオフラインイベントであるElasticON Tokyoが開催され参加しました。 参加しようと思ったのは、10月の頭にElasticのブログで公開された「Stateless — your new state of find with Elasticsearch」というアーキテクチャの変更がきっかけです。
(図はElasticのブログから引用)
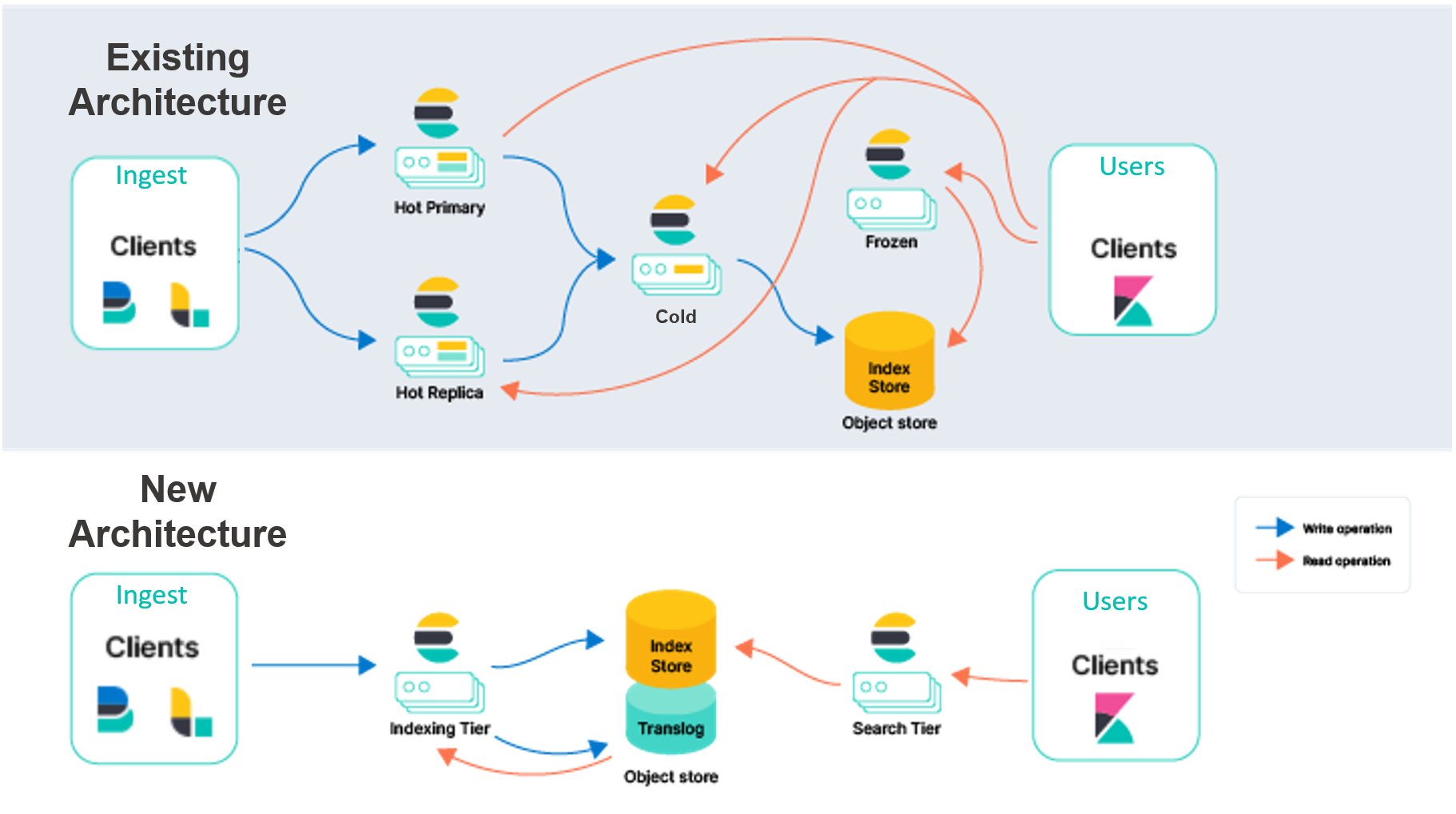
ElasticsearchはLuceneのインデックスを分散したシステムとしてスケールアウトできるようにするという目的でリリースされました。 インデックスをシャードという単位で複数のElasticsearchのノードにデータを保存し、レプリカを作ることで分散する仕組みを実装していました。 Elasticsearchでは、インデックスのレプリカは、作成したインデックスを定期的にコピーするのではなく、登録するデータがElasticsearchのクラスターにやってきた時に、 データ自体をコピー先にも配り、プライマリーやレプリカとなるシャードがあるノード上でそれぞれインデックスに登録する処理を行うという処理の流れです(古いけど、わかりやすい説明はこちら)。 この場合、インデックスにデータを登録する処理(転置インデックスのデータ構造に変換する処理など)は、レプリカの数だけ同じ処理がクラスター上で発生します。
この基本的なアーキテクチャをもとに、保持するデータの鮮度(新しいデータのほうが検索頻度が高い、インデックス登録する時はマシンは多く、古くなったデータが入ったインデックスはコストが低いマシンになど)などを元に、クラスター内のノードの特性を異なるものが混在するような複雑な仕組みを作ってきました。 いろいろなデータの持ち方などで多くのデータなどを保持できるようにしてきたのですが、クラスター全体としては、検索の負荷のピークをさばけるような構成を基本的に保持しておくというかんがえです。
ただ、昨今は必要に応じてスケールアウト(リクエストが増えたりデータ量が増えた時)、スケールイン(夜中は利用者が少ないからクラスターを小さくしたい時)できるような仕組みのほうが求められています。 そこで、発表されたのが上記のブログであり、上図の新しいアーキテクチャです。 計算処理(データを登録、検索する処理)とストレージを分離し、さらに登録する処理と検索する処理も分離した構成です。 このようなアーキテクチャにすることで、登録処理の演算コストがレプリカごとに必要ではなくなり、検索の部分だけだったり、登録の部分だけをスケールアウト・インできるような自由度が手に入ります。 また、ストレージ部分でレプリカを担保(S3とかのオブジェクトストレージで冗長性を担保)できれば、レプリカのストレージコストも必要なくなります。
というブログが発表されたのですが、詳細などはまだよくわからなかったのでElasticON Tokyoに参加して詳しい話が聞けるのかなぁと期待していました。
参加当日の朝のびっくりするニュース
11月30日の朝に起きて、出かけようかと思っていたところに、AWSのre:Inventで発表されたニュースが舞い込んできました。
ほー(まだタイトルしか読んでない)https://t.co/KK22duaBNH
— Jun Ohtani (@johtani) November 29, 2022
Amazon OpenSearchがServerlessオプションを発表というニュースです。 (Amazon OpenSearchとは、AWSがElasticsearchをフォークして始めた検索エンジンで、Amazon OpenSearch Serviceというのは、AWSがそれをSaaSとして提供しているものです)
まぁ、気になりますよね、「Serverless」ってキーワードに。 ElasticON Tokyoに向かう電車でブログを読んだり、どんな仕組みかを調べたので、それを簡単にまとめておきます。
- プレビュー段階(Tokyoリージョンではもう試せる)
- これまでのAmazon OpenSearch Serviceとは別(オンザフライで移行はできない?)
- 「コレクション」という単位でクラスターを管理(スケールインとかアウトとか)
- コレクションにはタイプがあり、タイムシリーズ(ログとか)か検索のユースケースなのかで使い分ける(公式ドキュメント)
- インデックス処理と検索処理で計算ユニット(OCU)が別々にスケールできる(下図)
- 作成されたインデックスはAmazon S3に保存され、そこで冗長性は担保される。(下図)
- 検索処理のユニットはS3のデータをローカルに持ってきて処理をできる
- データ登録とかのAPIは基本的にServerlessかどうかで違いはなさそう(これまで通りのクライアントでアクセスとかで競う)
- 設定した範囲でいいかんじにスケールアウトインしてくれそう(ほんとかな?)
- もちろん、いくつか制限がある(サポートしてないプラグインとか操作もある)
(図はAWSのドキュメントより引用)

発表時のブログでは詳しくはわからないのですが、公式ドキュメントではさらに詳しく説明がありました。 こちらを読むほうが仕組みがわかると思います。 今後もどんどんドキュメントは充実していくんだろうなと。今ならまだサクッと読める量ですw
ただ、「サーバーレス」という定義が私はよくわかりませんでした。 公式ドキュメントを読むとコレクションを作ると少なくとも4つのOCUが起動しているみたいで課金されると記載があります。
まぁ、Elasticの発表と同様に、これまでは最大負荷の時を元にクラスターを維持せずとも、より柔軟に検索だけ、登録処理だけを一時的にスケールできるとコストを下げられそうですね。 すぐに誰かが使ってみたブログなどを出してくれると思うので、細かな使用感などはそのうちわかってくるかと。
今後は?
ElasticもAWSも考え方の基本となっているのは、Berlin BuzzwordsでAmazonのMikeさん(Luceneのコミッター)が2019年に発表されたものだと思っています。 アーキテクチャの変更がどんな影響が出るかはわからないですが、少なくとも検索のユースケースでよりスケールアウトしやすくなるだろうなと。 どちらもSaaSとしての仕組みとして提供するので、検索エンジンそのものの機能として公開されるかはわからないです。 ですが、そのほかの検索エンジンも出てきていますし、今後も検索エンジンから目をはなせないです。 今回は残念ながら触っていませんが、時間を見つけて使ってみたいです(Elasticも早く出してくれないかなー)
ということで、当初の予定とは違うブログになってしまいました。。。 技術的な深い話はまたどこかで。。。
参考文献
- Stateless — your new state of find with Elasticsearch | Elastic Blog
- Preview: Amazon OpenSearch Serverless – Run Search and Analytics Workloads without Managing Clusters | AWS News Blog
- Berlin Buzzwords 2019: Michael Sokolov & Mike McCandless–E-Commerce search at scale on Apache Lucene - YouTube
comments powered by Disqus
