目次
Domain-Specific Pretraining for Vertical Search: Case Study on Biomedical Literatureという論文を読んだので軽くメモを残しておきます。論文自体はリンクから参照してください。
読んだ理由
Azure Cognitive SearchでSemantic Searchが利用可能になったこともあり、「Semantic Search」に関するMSのリサーチチームが発表している論文をたまたま見つけたためです。 Elasticsearchとニューラルモデルを利用したランカーでのリランクする仕組みがSemantic Searchと似ていたので読んでみました。
ざっくりメモ
どんなもの?
クリックログなどで関連度を改善できないような場合に、ドメイン固有の言語モデルを利用して検索結果の改善をする方法が提案されているので、バイオメディカル検索で実際に評価してみたという論文です。 特定分野の大量の文書から検索をするときに、ドメイン固有の事前学習した言語モデルを用意して、さらにファインチューニングする方法を評価しています。 言語モデルの生成に利用されたのはBERTになります。
技術や手法のキモはどこ?
医療分野のデータを利用して評価していますが、ほかのドメインにも一般化できる可能性があることや、実際のシステムを提示している部分が肝になりそうです。
論文から引用した言語モデルを用いてランキングを行う仕組みを構築する部分の構成です。

左半分が、ドメイン固有の事前学習についてです。Wikipediaなどを利用したBERTのモデルが公開されたりしていますが、大量のドメイン固有データが用意できるのであれば、ドメイン固有のデータで事前学習することが有効であるという主張です(参考文献。これもMS Researchでした。同じチームなのかな?)。 この論文ではBERTの学習データとして、ドメイン固有のテキストを用いています。 実際にはPubMedBERTを利用しています。
右半分がドメイン固有のデータで生成された言語モデルを利用して、ドメイン固有のニューラルランカー(検索結果のランキングを行なう仕組み)をファインチューニングする処理です。 MS MARCOと呼ばれるMSが公開している機械学習向けのデータセットのうち、ドメイン固有のサブセットを取り出して利用しているようです。
この論文では、L1検索(第1段階の検索)にBM25を利用して、L2検索にここで作成したニューラルランカーを利用し、検索結果を返す仕組みとなっています。 これは、Azure Cognitive SearchのSemantic Searchのシステムに似ています。
この論文では、BM25で検索した結果の上位60件の結果がL2のランカーの入力となっています。
以下の2つが主な論文の成果となっています。
- ドメイン固有の事前学習を利用することで、高度な学習コンポーネントなどの追加することなく高い精度が出た。
- 既存のBM25の検索エンジンと組み合わせてニューラルランカーを使うことで、計算コストを下げつつより良い上位の検索結果を返す仕組みを構築した。
どうやって有効だと検証した?
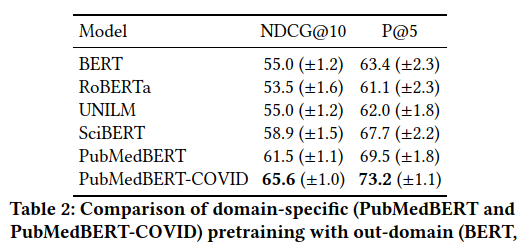
TREC-COVIDデータセットを用いて評価して、TREC-COVIDに参加しているシステムと論文で提案している構成のシステムとの比較をしています。 また、ドメイン固有の事前学習が、一般ドメインなどの事前学習と比較して影響があるかどうかの評価もしています。
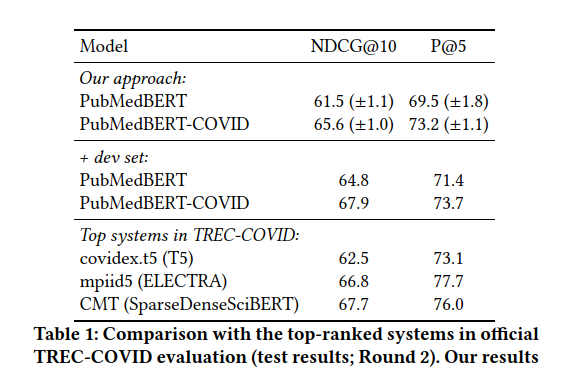
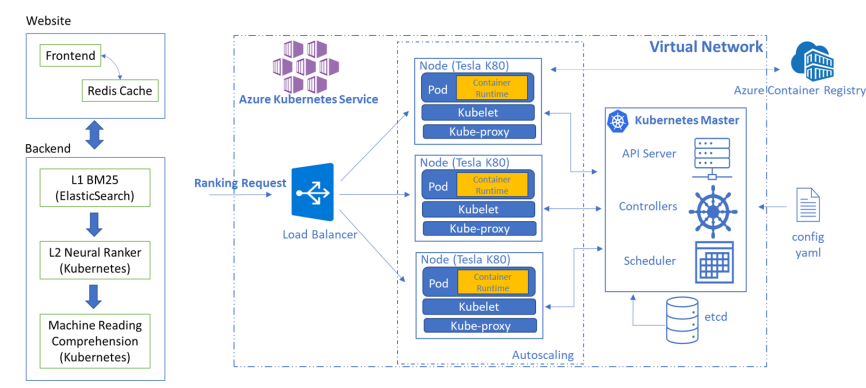
実際にAzure上で構築した仕組みをMicrosoft Biomedical Searchとして公開しているようです。 上記のシステム構成のように、Elasticsearchで検索して、ニューラルランカーはKubernetes上に展開されたGPUで計算をしています。 論文には使用しているマシンの構成や台数なども記載があります。
実際に構築したシステムをユーザーに利用して体験したもらった結果としては、 複雑な意図を持った長いクエリに対してはPubMedなどの他の検索ツールとしても良い結果が返ってきたことが確認されたとなっています。 ただし、一般的な短いクエリの場合は十分な結果にならない場合があったとのことです。
議論はある?
実際にほかのドメイン(金融、法律、小売りなど)で適用してもうまくいくかは今後の研究に期待だと思います。 また、ファインチューニングするときに利用できるデータが今回の論文にあるようにMS MARCOのサブセットとして抽出できればよさそうです。
他に読むべき論文は?
TREC-COVIDに参加しているほかのシステムがどのような学習や仕組みが必要なのかを見ることで、どのくらいの手間・コストが軽減しているのかがわかるはずです。
感想
ということで、読んでみました。 細かなほかの手法については調べていませんが、システム構成としてはAzure Cognitive SearchのSemantic Searchの仕組みと同じだと思われます。 違いは、ドメイン固有の事前学習のモデルではないことでしょうか。 ある程度のドメイン固有のモデルを利用できる仕組みができると、さらにSemantic Searchがうまく使えるようになるのかもしれません(前回書いたブログではWikipediaのデータを利用してみましたが、思ったほど良い感じはしなかったです。。。ファインチューニングの仕組みもないしなぁ)。 また、短いクエリでは芳しくない結果もあったというのは、おそらくニューラルランカーで評価するための情報が少なくなってしまうのだと思います。Semantic Searchに向いているクエリの作り方とかが出てくるのかな?
comments powered by Disqus
See Also by Hugo
- Cloudera Searchメモ(妄想版)
- Extreme Multi-label Learning for Semantic Matching in Product Searchという論文を読んだ
- JustTechTalk#02 形態素解析のあれやこれや@ジャストシステムに参加しました。
- Oramaという検索エンジンでブログ検索を作ってみた
- 今年もオンラインでBerlin Buzzwordsに参加した
