目次
年末までに知り合いと次の論文を読んだので軽くまとめておきます。
なんで読んだの?
前回読んだ理由と一緒ですが、Semantic Searchに絡んだ検索の論文であり、Amazonの製品検索での話も関係していたので読みました。
どんな論文?
Amazonの製品検索でセマンティックマッチングを利用する方法、レイテンシを低くしつつ再現率を改善できるような仕組みを検討して評価した論文です。 実際には商品検索のマッチングを大規模なマルチラベル問題(Extreme Multi-label Classification:以下ではXMC問題とする)として定義して、その問題を効率よく解く方法について検討評価しています。
検索には大きく2つのフェーズがあります。マッチング(クエリにヒットした文書の集合を求める)とランキング(マッチングのデータを関連性の高い順序で並べる)です。 前回のMSの論文では、マッチング後のランキングのフェーズで言語モデルを利用した並び替えを行う話でした。 今回の論文ではマッチングに関してセマンティックサーチを有効活用できないか?という論文になります。 転置インデックスベースの(語彙による)検索では、スペルミスや類義語などを検索することが難しいです。 語彙以外のデータ(クリックや購入といったユーザーの行動や製品の意味的表現など)を学習できる埋め込みベースのニューラルモデルを活用して、マッチングを補完する方法を検討しています。 下図のようにあくまで転置インデックスベースの検索の補完として利用するみたいです(論文に掲載されていたアーキテクチャ)。
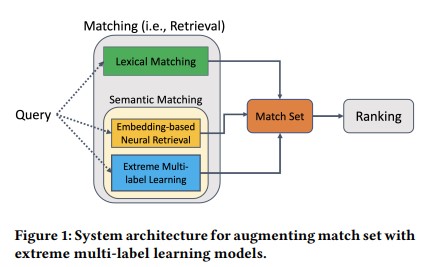
XMC問題とは?
セマンティックサーチを行なう場合、埋め込みベースのニューラルモデル(例えばBERTとか)を利用することが多いですが、 クエリトークンを埋め込み空間にベクトル化する部分が推論のボトルネック(レイテンシが高くなる)になることが多いです。 これは、ニューラルネットワークの複雑さに依存します。 低レイテンシになるように、複雑ではないエンコーダーを用いることもありますが今度は性能(精度)が良くなくなります。
そこで、この論文ではセマンティックマッチングをXMC問題として定義し、これを効率よく解くための手法を提案しています。 ここで、XMCの問題とは、入力(今回はクエリ)に対して、最も関連性の高い複数のラベル(今回は製品)を出力することとなります。 Amazonでの製品なのでほんとに大規模(ラベル=製品=1億件)です。
従来のXMC問題を解くための手法として、疎な線形モデルの手法、パーティションベースの手法、グラフベースの手法などが列挙されています。 疎な線形モデルの手法では、ナイーブなOVR(one-versus-rest)だと出力となるラベルの数に対して線形に推論時間も大きくなるため、今回の用途には適しません。 この論文ではパーティションベースの手法として、推論時間を短くできるツリーベースで疎な線形モデルの手法を評価しています。
どういう仕組み?
ツリーベースのモデルは次のような感じです。 PECOSのXR-Linearモデルを利用しています。 モデルに関する詳細についてはこちらの論文に詳しく載っているようです(まだ読んでいないです、、、)。
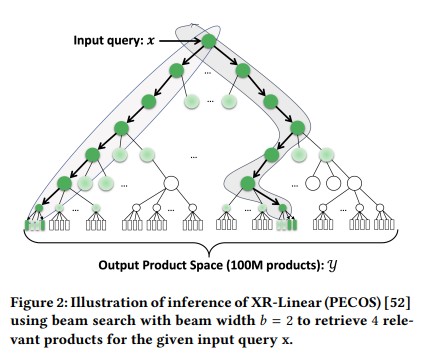
一番上に入力として与えられるxがクエリ(ベクトル)で一番下の四角が製品にあたるラベル(Y={1,...,l,...L})です。
これらが与えられたときに最も関連性の高い上位k件のラベル(製品)を出力するモデルを生成します。
モデルのパラメータは、学習データとして(x, y)(ここで、y∈{0, 1}^𝐿、すなわちクエリに製品がマッチするかしないかの二値)を使って調整します。
これは、ツリーのそれぞれの階層のノードで、その下の層に関連するデータがあるかどうか?という分類を学習すればよいことになります。 学習データとしては、入力と最下層のラベルにマッチするかどうかというデータです。 これをもとに、ツリーの最下層のデータをもとにひとつ上の層の分類器の学習をすればよいことになります。
推論は出来上がったツリーベースのモデルに対して、ビームサーチで行ないます。 この時、それぞれの層のノードの分類器では推論の効率化のために枝刈りの閾値を設定しています。 本論文で閾値の違いによる精度とレイテンシの比較も行われています。 また、ビームサーチのビームサイズを変化させた場合の性能についても実験しています。
どうやって検証した?
次のようなデータを用いてAWS上にモデル構築、推論のシステムを用意し実験しています。
- 10億件以上のポジティブなクエリ-商品ペアのデータセット
- クエリ:2億4千万、商品:1億
- ポジティブなペアとは、クリック数や購入数の集計値が閾値以上。ただし、データセットとしては集計値は利用していない。
- トレーニングセット:12か月分の検索ログ
- 評価用テストセット:1か月分の検索ログ(12%の製品はトレーニングセットには出てこない)
というデーセットをもとに上記のモデルを学習しています。 特徴量はクエリテキストと製品のタイトルをもとにTF-IDFをいくつかのパターンで導出したものが使われています。 詳しくは論文の結果に関する表などを見ていただくとして。。。
結果として、1億件の商品カタログで60.9%のRecall@100を1.25ミリ秒/リクエストという低レイテンシで達成したとなっています。
気になる点は?
知り合いと3人で読んでいて次のような気になる点が出てきました。
- ツリーの構築をするときに、製品のラベルの並び順(製品のクラスタリング?に他製品が似た場所に来る感じ)が推論の効率の良し悪しに影響するんじゃないの?=Amazonではないところではうまくいかない?
- PECOSの論文読まないといけない?
- 製品が増えたときにモデルの組み換えとかどうするの?
- コールドスタート問題という形で今後の課題として書かれていたので、今後に期待
- 転置インデックスでのマッチングの補完として利用しているということだったけど、ランキングはどうしてるんだろう?
- 別のランキング用の指標があるのかな?上位k件とした場合にどうやって、決めているのか?
- モデル更新のタイミングはどのくらいのスパンなんだろう?
まとめ&感想
セマンティック検索の処理を分類問題に置き換えてその手法を用いて行い、実際のシステムに適用できそうな速度と精度を出しているのが面白かったです。 セマンティック検索にもいろんな手法があるのだなと(そして、いろいろ勉強しないといけないんだなと。。。)。
気になる点にも書きましたが、ツリーの作り方になにかコツがあるのか?他の検索結果と組み合わせるときに、どのような基準で上位を選択しているのか?など疑問点も残っています。 個人的には特にどのように既存のシステムにくっつけていくのかというところが気になっています。 論文の続編でその辺の話が出てくるのかなぁ?
ツリーの作り方に関するPECOSの論文を誰か解説してくれると嬉しいかもなぁと思いつつ、とりあえずブログに書き残してみました。参考になるかなぁ。。。
参考文献
- Extreme Multi-label Learning for Semantic Matching in Product Search - ACM
- Extreme multi-label learning for semantic matching in product search - Amazon Science
- PECOS: Prediction for Enormous and Correlated Output Spaces
- 数えきれないほどの分類を行うExtreme Classification - Technical Hedgehog
comments powered by Disqus
See Also by Hugo
- Domain-Specific Pretraining for Vertical Search: Case Study on Biomedical Literatureという論文を読んだ
- ElasticsearchのアーキテクチャとStateless / Serverless
- Querqyの調査(その1)
- Elasticsearch Marvelの紹介と第一印象
