目次
金曜日に引き続き、イベントに参加して来ました。(仕事。。。これも仕事だよ。)
「Hadoop Conference Japan 2013 Winter」です。 普段、Hadoopを触るのも少ないのですが情報を仕入れときたいなぁということで。
今年はビッグサイトですよ。そろそろ無料のカンファレンスもキツイのではないでしょうか。。。 こちらの写真はセッション会場。今回もすごいです。。。

簡単ですが、聞いていた感想です。 全体的に、Hadoop本体の話ではなく、エコシステムと呼ばれる周辺のプロダクトの話や実際に運用している実例が増えていました。 だいぶ普及期に来たのかなぁと。そして、自分の不勉強を実感できたなぁと。 (あと、TreasureDataに絡む話が多いなぁと言うのも印象です。そういうセッションを選んで出ていたのかもしれませんが) 懇親会まで残っていたのですが、結構、すごい方たちの顔ぶれだなぁというのを今更ながらに実感するとか。 (ハチ象Tシャツを着ているすごい集団でもありましたが。。。)
以下はいつものメモになります。だいぶ金曜日のイベント後で腑抜けてるのでメモが雑ですが。
◯ご挨拶
Doug Cuttingさんのビデオ(あんまり聞けてない) さすがのhamakenさんのトークの安定感。
後援はリクルートテクノロジーズさんが大半。
リクルートテクノロジーズの米谷さんが軽く発表
◯LINEのHBaseを利用した大規模なメッセージストレージ:NHN Japan 中村 俊介
まずは、LINEの紹介が続く。
New Yearのメッセージは3倍位だったけど、何とかなっったよと。
データロスがない。
サーバ故障からのデータリカバリも自動でやってくれる
書き込み1ms、読み出し1-10msでできてる
・IDC onine migration
クライアントベースで2つに書き込み
Incremental replication(新データ)、BulkMigration(旧データ)
元のHBaseのレプリケータは利用してない(pushだったから。スループットコントロールしたかったから)
・NN failover
2012.10にNameNode障害発生
HA構成にしてたから問題が発生。
VIPはHDFSにつかうとリスキー
現在:
少ないダウンタイムを許容する
・Stabilizing LINE message cluster
※あとでHBase触るときに資料見直すくらいで。。。
Case1:Too many HLogs
Case2:Hotspot問題
まぁ、けど1億ユーザのインフラとして使えるってすごいよな。。。
◯Hadoop meets Cloud with Multi-tenancy: Treasure Data 太田 一樹
TDもFluentdも有名だなぁ
Hadoopのメンテナンスとか、つらいよねというのを見てきたのでTD作った
・なぜ、BigData+Cloud?
Hadoopだけみてもバージョンが混在してる+ディストリビューターも多くなってる
十徳ナイフみたいになってきてるけど、必要なのはナタだよね。というのを提示するためにTD立ち上げた。
・なぜCloud?
・IaaSベンダーの対象としてるのはSCM。
オンプレだとHWが陳腐化してくよね→HWはクラウドが主流に
・PaaS、SaaSの対象は時は金なり
バージョンアップとか大変だよねと
・TDのご紹介
唯一の解析用DBを目指して
・哲学とアーキテクチャ
解析とか運用をいかに楽にしていくかというのを主体においたサービスを提供したい?
いかに速くレポーティングシステムを簡単に構築していくかとかの話
簡単なインタフェースと目的に集中することで、価値を提供
・AWSとの違いは?
・アーキテクチャとか技術的な話
データを集める処理がデータ解析に実際には重要なフェーズ
・カラム指向でデータ保存
実装がどーなってるのかとか、TD内部のHadoopクラスタの運用、バージョンアップとかがどうなってるのかもきになる。(企業秘密だろうけど)
◯Amazon Elasti MapReduceとHadoopコミュニティの関わり:Amazon Web Services Peter Sirota
・3つのV
Volume、Velocity、Variety
・yelpのAuto-suggestの例
カスタマーのレコメンデーションにElasticMapReduce使ってるよと。
・razorfishの広告インプレッションの解析に使ってる
・Amazon.comでの話
AWS Public Datasetsの話
http://aws.amazon.com/jp/publicdatasets/
IonFluxのDNA解析の話
・いろんな分野でのBig Data
事例がちらほら
※わかりやすい英語なんだけど寝不足が。。。
◯ランチ!
サンドイッチと豚汁とあとなんとかライス。
TDブースにて、fluentdのTシャツもらったよ!
◯Hadoop's Power to Transform Business:MapR Ted Dunning
・Mahaut+Solrの単語が。8時間のレコメンデーションデータの作成が3分に??
・Stormにてリアルタイム処理と連携。バッチ処理はMRで。
・バッチ処理とリアルタイム処理の間としてのDrill
・Drillの概観とできるところの話。
(あとでスライドで)データ解析のために機会学習の処理とかも投げられそう。
Q:ImplaraとDrillの違いは?
コミュニティベースかなどが違うよね(あまり聞き取れず)
Q:Drillの開発はどのくらいすすんでるの?
A:。。。
Q.クエリ言語としてSQLがいいの?
A.No。というのも、単独の言語ですべてにベストというのはないから。SQLはわかりやすくて良いが、実行が非効率な場面も。
◯Introduction to Impala~Hadoop用のSQLエンジン~:Cloudera 川崎 達夫
・Impalaとは
分析に特化した低レイテンシクエリ実行基盤
Apacheライセンス
バッチ処理要ではなく、データサイエンティストが試行錯誤するときに利用するのを想定
パフォーマンスが良い
実行エンジンはC++とかで実装されてる
MapReduceに依存してない
・MapReduceの問題点
MR直接は難しい→Hiveとか、M/Rの実装を隠して使いやすくするものが増えてきた
Hiveを例に説明。MRがベースなので高レイテンシ
・Impalaのアーキテクチャ
機能制限やGA版について言及されてる資料なのが良い
・GA以降の話もあり
ピンチヒッターなのに落ち着いて発表とか凄すぎです。
jdbcサポートも入ると。
プランナーはjava実装
Hiveとの互換性は?→完全互換を目指す。
開発のプロセスが見えにくいのでは?開発主体がcloudera
◯Flumeを活用したAmebaにおける大規模ログ収集システム:CyberAgent 飯島 賢志
立ち見。
Flumeのコミッターの人がCAにいたんだ。
◯Log analysis system with Hadoop in livedoor 2013 Winter:NHN Japan 田籠さん@tagomorisさん
・NHNJapanのお話
・Webサービスのログ解析について話していく
400+Webサービス
・2011年8月にLTしました。
・1.5TB/day。。。
・batchとstream
Batch集計も重要だし、Stream処理も重要なので、ハイブリッドシステム
・システムーバービュー
FluentdClusterを中心にして各種ツール、保存先に転送してる。
これが結構重要。だけど、今日はFluentdの話ではない
・Fluentd周りを一人でやってるのか。。。
・処理の流れ
・ログの収集と、生ログ保存
・パース(主にHive用に)、変換、フラグ追加(分類しておくとあとで集計したいとか、保存すべきかを処理可能に)
・Hiveにロード
・第1世代のはなし
すべてbatch処理、Scribe
遅延が1時間ちょっとあるため、Hiveクエリで結果が見れないとか。
・第2世代の話
Fluentdのstream処理にHadoop Streamingを呼び出せるようなプラグインを書いた
Fluentd+HoopServerの構成
・第3世代
HoopをWebHDFS
Fluentdでのオンライン集計
GrowthForcast、HRForcast
・第4世代(ここ1週間でやったこと)
CDH4でQJMベースのNameNode(Failoverは手動)
Hiveのスキーマを変更(これはブログに今度書くよ)
とりあえず、現時点で改善点が思いつかない
・総括
HTTPベースでRPCベースにしたのでコンポーネント切り替えが結構楽
OSSで公開されてるからいいよね
公開することにより色々とドライブするよ!
◯いかにしてHadoopにデータを集めるか:Treasure Data 古橋 貞之
・自己紹介
・ビッグデータ収集の問題点
・壊れたデータが入ってる
・読み書きの時間がかかる
ログはサブケースである。メインはサービスとかだから。
・トライ&エラー処理が時間かかる
・データを分割するのが基本的なアイデア
失敗した時のリトライが楽になる。さらに、それをStream処理すれば良いよねと。
・flumeのお話
・fluentdのお話
バッファリングは性能アップも兼ねてる
設定のクラスタへの伝搬とかインストールはpuppetとか使おうねと。
プラグインのインストールが楽
・いくつかのプラグインの紹介
・TDへのデータ投入のお話
・最後にmuddydixonさんのプラグインの宣伝がw
◯Hadoopの次に考える分散システム技術:Microsoft 萩原 正義
・CAP定理の克服をどうしていくか
・CAPのおさらい
・Lease
クライアント主導、サーバ手動とか
(理論重視の話で最後のセッションには辛かった。。。頭が疲れててついていけませんでした)
おまけ 今回頂いたノベルティなどを写真に撮ってみました。(ランチはお腹すいてて写真取らずに食べちゃいました。。。)
Hiveロゴへの愛を語ってHive Tシャツをゲット。 FluentdのTシャツももらいました! Hiveステッカーなどもゲット あと、メッセージボードなるものがあったので書いてみました。一応、Hadoopに絡んだことですよね!?
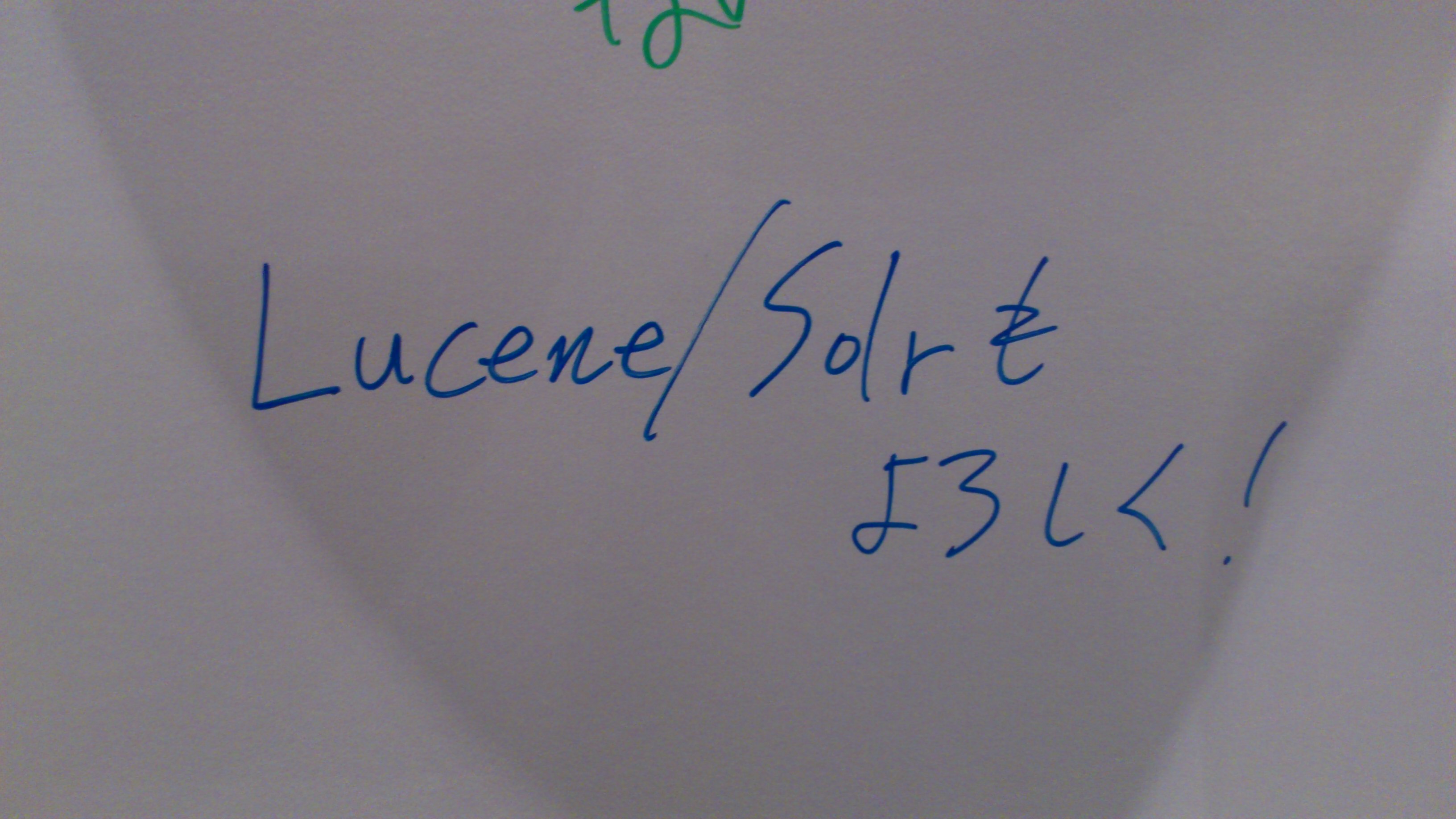
comments powered by Disqus
See Also by Hugo
- MapR中身説明会に参加しました。(Jugemより移植)
- Cloudera World Tokyo 2013に参加しました! #cwt2013
- 『プログラミング Hive』 『Hadoop 第3版』刊行記念セミナーに参加しました! #oreilly0724
- Heroku Meetup #8 TreasureData + Waza Report!! に参加しました。#herokujp(Jugemより移植)
- エンジニアサポートCROSS 2013に参加(+お手伝い+モデレータ)しました #cross2013(Jugemより移植)
