目次
お手伝いしているお客さんがAzure Cognitive Searchを利用してます。 検索周り=Azure Cognitive Searchに関する手伝いをする形で入っており、 いくつか触った感触をブログにまとめてみようかと(お客さんからはOKいただいてます)。
Azure Cognitive Searchとは?
「AIを活用した」クラウド検索サービスと紹介されています。
昔はAzure Searchと呼ばれていましたが、ここ最近はAzure Cognitive Searchと呼ばれているみたいです(Microsoft Igniteで発表された話がまとまっているページもあります)。 もともと、検索エンジンのSaaSサービス(キーワード検索、あいまい検索、オートサジェスト、スコアリングなどの機能)として作られていた部分に、データの登録パイプラインにCognitive Serviceの便利な機能を簡単に使えるようにしたものというイメージでしょうか。
バックエンドはElasticsearchのはずです。変わってなければ。 昔、Elastic社主催のユーザーカンファレンスでMSの方が公演された資料が公開されていたりします。 ちなみに質問が多いのでしょうか、Azure Cognitive SearchとElasticsearchの違いはなんですか?というページがよくある質問のページに用意されていました。参考までに。
今回はちょっとしたインデックスをつくって検索する部分を紹介してみようかと思います (Cognitiveなところは機会があればまた)。
普通の使い方については、Azureのドキュメントなどを読んで頂く形にします。 ポータルと呼ばれるブラウザ上でAzureのサービスを触ることができる画面が用意されています。 ここで、簡単な操作(インデックス作成、フィールドの追加)
APIを使ってインデックス(特にAnalyzer)の設定をしたり、データをいれて、クエリしてみるというところをサクッと紹介しようと思います。
インデックスの作り方
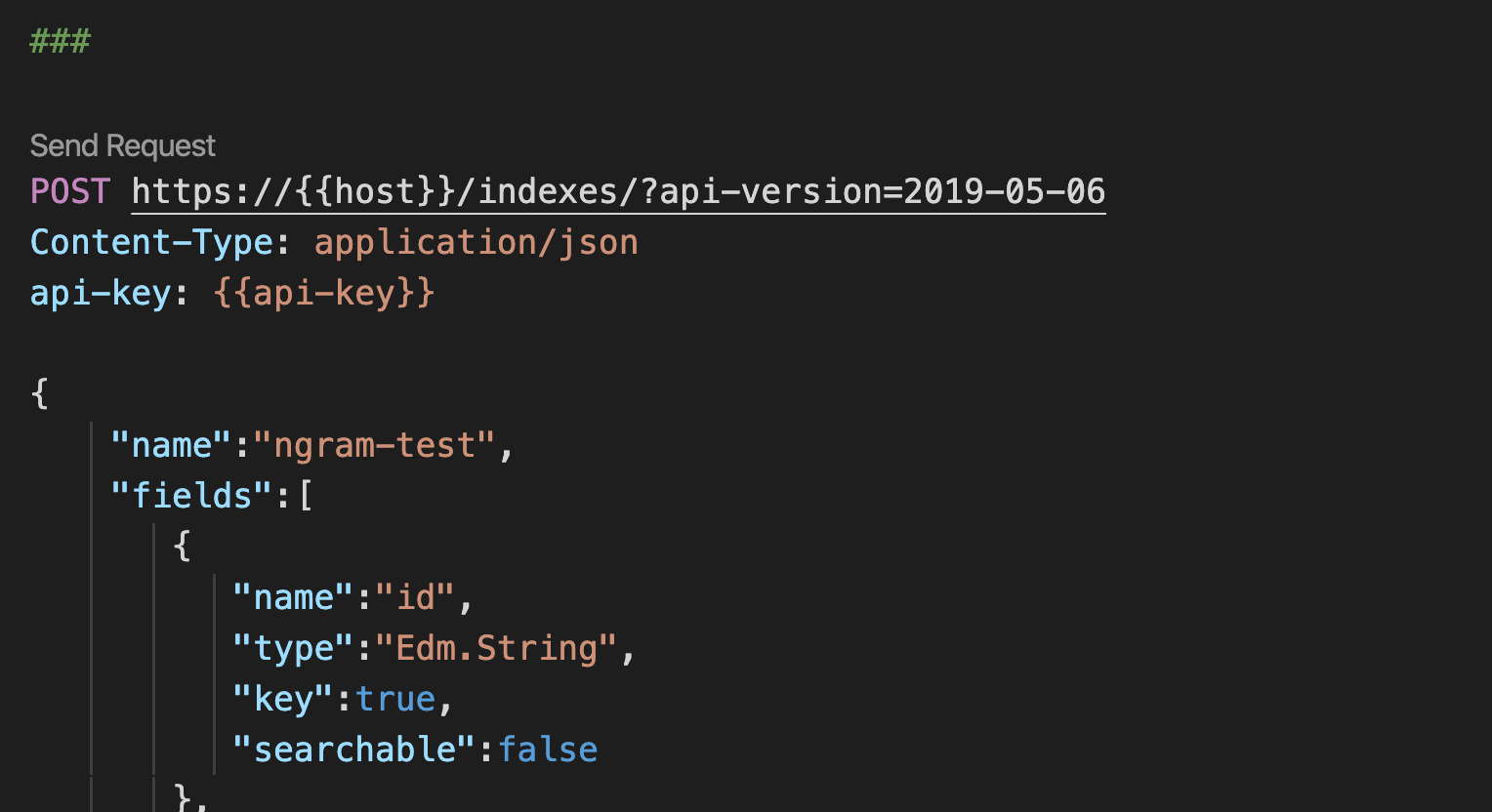
インデックス作成に関するドキュメントも用意されています。最初はポータル(GUI)でインデックスを作成する方法が紹介されています。 ですが、今回はn-gram(n=2)のAnalyzerを利用したかったので、GUIではなくAPIでインデックスを作成しました。 カスタムアナライザーを利用する場合、REST APIを利用しなければ行けないということになっています。 n-gramのAnalyzerを含むインデックス生成のREST APIは以下のとおりです。こちらを実行することで、インデックスが作成されます(JSONの記述ミスなどがある場合はエラーが返ってきます)。
@host = <サーチのサービス名>.search.windows.net
@api-key = <APIキー>
###
POST https://{{host}}/indexes/?api-version=2019-05-06
Content-Type: application/json
api-key: {{api-key}}
{
"name":"ngram-test",
"fields":[
{
"name":"id",
"type":"Edm.String",
"key":true,
"searchable":false
},
{
"name":"ngram",
"type":"Edm.String",
"searchable":true,
"analyzer":"bi_gram_analyzer"
}
],
"analyzers":[
{
"name":"bi_gram_analyzer",
"@odata.type":"#Microsoft.Azure.Search.CustomAnalyzer",
"tokenizer":"bi_gram_tokenizer",
"tokenFilters":[
"lowercase"
]
}
],
"tokenizers":[
{
"name":"bi_gram_tokenizer",
"@odata.type":"#Microsoft.Azure.Search.NGramTokenizer",
"minGram":2,
"maxGram":2
}
]
}
なんだかどこかで見たことのある記述のようなそうでないような。。。
Analyzerは、charFilters(0以上複数可)、tokenizer(1つ必須)、tokenFilters(0以上複数可)から構成されます。
フィールドで指定するのはAnalyzerなので、まずanalyzersにCustomAnalyzerの設定を行います。
名前はbi_gram_analyzerにしました(好きに付けてください)。
tokenizerにはこのあと設定するtokenizerの名前を設定します。ここでは、bi_gram_tokenizerという名前にしています。
また、大文字小文字を気にせずに検索したいため、tokenFiltersにlowercaseを指定しています。こちらはすでに定義済みのため、定義済みの名前で呼び出すだけで使用できます。
次が、bi_gram_tokenizerの設定です。
n=2としたいので、tokenizers配下にTokenizerの設定をします。
@odata.type":"#Microsoft.Azure.Search.NGramTokenizerがTokenizerの名前です(ちょっと独特な名前ですね)。
Tokenizerごとにオプションがあり、NGramTokenizerの場合は、minGram、maxGramがオプションに相当します。
今回は2文字ごとにトークンを出力したいので、minとmaxをそれぞれ2としています。
これで、あとは、フィールドでanalyzerという設定にbi_gram_analyzerを指定すればそのフィールドはbi_gram_analyzerを使用してアナライズされるようになります(このへんはElasticsearchといっしょですね)。
フィールドは文字列を扱うので、Edm.Stringというタイプにしてあります。データ型については、フィールドコレクションとフィールド属性というドキュメントを参考に設定しましょう。
閑話休題 - REST Client Exstension for Visual Studio Code
なお、今回のサンプルはREST Clinet Extention for Visual Studio Codeを利用する想定の記述になっています。
Visual Studio Codeで.restもしくは.httpというファイルに以下のAPIを記述すると、Send RequestというリンクがURLの上部に出てくるような拡張機能です。REST APIにリクエストするときに便利なツールになっています。
変数も使えるので、APIのキーやURLの一部をこのように共通化して、他の環境でも使いやすくできるのは素晴らしいなと。
アナライザーの挙動の確認
設定したAnalyzerがきちんと機能しているかというのを確認する必要があります。 入力した文字列がきちんと想定している単語として切り出されて、転置インデックスの見出し語に使われるかというのが重要になるからです。
Azure Cognitive Searchでもアナライザーのテスト用APIが用意されています。
使い方はこちら。
APIの仕様のページもありました。
「アナライザーの挙動はどんな感じ?」という文字列が、作成したインデックスの定義したアナライザーbi_gram_analyzerにより、
どのように分割されるかを確認するAPIの呼び出しは以下のとおりです。
###
POST https://{{host}}/indexes/ngram-test/analyze?api-version=2019-05-06
Content-Type: application/json
api-key: {{api-key}}
{
"analyzer":"bi_gram_analyzer",
"text": "アナライザーの挙動はどんな感じ?"
}
レスポンスはこんな形です。ヘッダ部分は省略してあります。
{
"@odata.context": "https://{{host}}.search.windows.net/$metadata#Microsoft.Azure.Search.V2019_05_06.AnalyzeResult",
"tokens": [
{
"token": "アナ",
"startOffset": 0,
"endOffset": 2,
"position": 0
},
{
"token": "ナラ",
"startOffset": 1,
"endOffset": 3,
"position": 1
},
{
"token": "ライ",
"startOffset": 2,
"endOffset": 4,
"position": 2
},
{
"token": "イザ",
"startOffset": 3,
"endOffset": 5,
"position": 3
},
{
"token": "ザー",
"startOffset": 4,
"endOffset": 6,
"position": 4
},
{
"token": "ーの",
"startOffset": 5,
"endOffset": 7,
"position": 5
},
{
"token": "の挙",
"startOffset": 6,
"endOffset": 8,
"position": 6
},
{
"token": "挙動",
"startOffset": 7,
"endOffset": 9,
"position": 7
},
{
"token": "動は",
"startOffset": 8,
"endOffset": 10,
"position": 8
},
{
"token": "はど",
"startOffset": 9,
"endOffset": 11,
"position": 9
},
{
"token": "どん",
"startOffset": 10,
"endOffset": 12,
"position": 10
},
{
"token": "んな",
"startOffset": 11,
"endOffset": 13,
"position": 11
},
{
"token": "な感",
"startOffset": 12,
"endOffset": 14,
"position": 12
},
{
"token": "感じ",
"startOffset": 13,
"endOffset": 15,
"position": 13
},
{
"token": "じ?",
"startOffset": 14,
"endOffset": 16,
"position": 14
}
]
}
このAzure SearchのAnalyze API、使用できるオプションはすくないですが、ElasticsearchのAnalyze APIと似ています。
データの登録の仕方
データ登録もAPIからできます(あたりまえですね)。 APIは1件ずつではなく、バルクで登録できる形で提供されています。
サンプルとしては、以下のような形です。
@search.actionの部分(searchがあるとわかりにくい気がするけど。。。)が、ドキュメントの登録、更新、削除の命令を書き込むところになります。
今回は単純に登録するだけなので、uploadを指定しました。
ほかにもいくつかアクションが用意されています。用途に合わせて指定する感じになります。
id、ngramはそれぞれフィールド名です。ドキュメントに登録したい値を記述します。
POST https://{{host}}/indexes/ngram-test/docs/index?api-version=2019-05-06
Content-Type: application/json
api-key: {{api-key}}
{
"value": [
{
"@search.action": "upload",
"id": "1",
"ngram": "新しいAzure Searchの使い方"
},
{
"@search.action": "upload",
"id": "2",
"ngram": "Elasticsearchの紹介"
}
]
}
検索クエリ
最後は検索クエリです。
検索クエリはいくつかのオプションがあります。
ざっくりだと、queryTypeがsimpleとfullという2種類が用意されており、ちょっとした検索を作る場合はsimpleで事足りそうという感じです。
入力された単語(スペース区切りで複数扱い)をフィールド(複数可)に対していずれかの単語を含むもしくは、すべての単語を含むという検索に行くというパターンですね。
このときの、「いずれか」か「すべて」の設定がsearchModeというパラメータになります。
anyの場合、Googleの検索と同様に、どれかの単語が入っているドキュメントが対象に、allの場合すべての単語が含まれるドキュメントだけがたいしょうになるといった形です。
queryType=fullの場合はLuceneの構文でクエリがかけます。ElasticsearchのQuery String Queryみたいな形です。
簡単なサンプルは次のような感じです。このサンプル
POST https://{{host}}/indexes/multi-field-test/docs/search?api-version=2019-05-06
Content-Type: application/json
api-key: {{api-key}}
{
"search": 'ngram:"使い方" ngram:"紹介"',
"queryType": "full",
"searchMode": "any"
}
すこしだけクエリの補足を。 searchに入力された単語をダブルクォートで囲んでいます。これは、「使い方」という文字がbi_gram_analyzerにより「使い」「い方」に 分割されるのですが、必ずこの順序で出現したものだけを検索対象にしたい(フレーズ検索)という意味になります(*bi_*gramなので、「紹介」に関してはダブルクォートは厳密には必要ないです)。
あと、レスポンスは今回記載していませんが、@search.scoreという項目で、スコアが返ってきます。
デフォルトのスコア計算には何を使ってるんだろう?ドキュメントにはTF-IDFとの記述があるのですが。。。カスタマイズもできそうです。
少しオモシロイと思ったのは、スキーマ(インデックスの設定)に定義されているが、ドキュメントとしては登録していない項目についても、
Azure Cognitive Searchはドキュメントのフィールドがnullという形で返ってくるようでした。
そもそもフィールドが存在しないドキュメントとフィールドの値がnullのものの違いは無いようです。
簡単ですが、インデックスの設定、ドキュメントの登録、検索の方法の紹介でした。
ちょっと触った感想
一番売りである、Cognitiveの部分はまだ触っていないです、すみません(こっちが売りな気もするんですが)。 検索エンジンの部分としては、Elasticsearchを知っていると、「あー、そんな感じね」という気持ちになれるサービスです。 個々のAPIやデータの形式は異なるので、きちんとAPIのリファレンスなどを確認しつつという形になりますが、なんとなくこういうAPIなどがありそうだな?と予測しつつ使えるかなと。 内部的にはElasticsearchだと思いますが、独自のAPIでラップされているおかげで、バージョンの違いなどを意識せずに使えるのではないかと思います。
また、今回は紹介していませんが、マイクロソフト独自の各言語のアナライザー(日本語も含む)があります。 Luceneのアナライザーとマイクロソフトのアナライザーのどちらも利用できますので、ここの違いを見てみるのも面白そうだなと思いました。 緯度経度を利用した検索、フィルター検索(スコア計算対象にならない)、ファセット、スコア調整の機能なども備えているようです。
なんにせよ、利用する場合やドキュメントを読む場合に、全文検索の仕組みをなんとなく知っておいたほうが読みやすいんじゃないかなというのが感想です。
ここ数年はElasticsearchがメインでほかはほぼ触っていない状況だったので新しい製品に触れるのは面白いですね。 時間があったら、アナライザーの違いなども調べてみたいなと思います。
comments powered by Disqus
See Also by Hugo
- インデックスエイリアス - Azure Cognitive Searchの新機能
- Visual Studio Codeのプラグインを作ってみた(Azure Search Analyze Client)
- Azure Cognitive Searchの新機能、Semantic Searchを試してみた
- TerraformでAzure Cognitive Searchのクラスターを起動
- Azure Cognitive Searchのリクエストのロギング
