目次
Azure Cognitive SearchにはOData式という書式で条件が書ける仕組みがあります。
ODataは検索条件($filter)やソート条件($orderby)、取得する項目名の指定($select)です。
私は、Luceneの構文に慣れているので、普通のsearchパラメータを利用しようとします。
が、OData式として特殊な書き方がいくつかあるようなのでこちらの利用方法も調べてみました。
その時、N-Gram(よくやるのはN=2)で陥る問題の話もあるのでこちらについても言及します。
OData式で検索
次のような3件のドキュメント(フィールド名はbodyとします)をN-Gramで登録していたとします。
ミルクティを飲みたいです。マティーニはカクテルですが、ミルクセーキは?風呂上がりのミルクは最高です。
この時、OData式でミルクティという単語で検索してみましょう。
検索条件は$filterで指定します。
フルテキスト検索用に関数が用意されており、こちらに単語を指定します。
$filter=search.ismatchscoring('ミルクティ')
こんな感じ。フィールドの指定がない場合、対象のフィールドは検索可能なフィールドすべてが検索対象になります(公式ガイドのクエリパラメータのqueryTypeに説明あり)。
では、実行してみましょう。で返ってくるのは?1だけかな?と思う人が多いかもしれません。 が、結果は3件とも帰ってきます。
問題点は?
では問題点はどこでしょう?
ismatchscoringのオプションなどを見る前に、転置インデックスを用いた検索エンジンの挙動をおさらいしましょう。
転置インデックスの仕組みを理解することで、なぜそんな挙動になるのか?というのがわかりやすくなります。
おさらいにはElasticsearchをベースに話をしますが、Azure Cognitive Searchでも同じような挙動になります。
転置インデックスとトークナイザー(アナライザー)の関係(おさらい)
昨年、オンラインで開催されたOSC広島で発表した資料(録画あり)でもざっくりと説明しています。
View 本当にその検索は自分が想像している検索になってますか? on Notist.
ざっくりですが、おさらいです。
検索エンジンでは、入力された文章を、ある規則(アナライザー)で単語に分割し、その単語ごとにどのドキュメントに出現したのか?というリストが作られます。 このリストが転置インデックスです。書籍の後ろにある索引を想像するとどんなものかがわかりやすいです。 単語に対してその単語が出てくるページ番号がわかるという仕組みです(下図は本の索引の一例)。

書籍の索引は著者や編集の方により厳選された単語のみが採用されています。 が、検索エンジンでは文章を単語に区切る機能が存在します。 この「ある規則」で単語を区切る仕組みが「アナライザー(トークナイザー)」と呼ばれる機能です。 例えば英語用のアナライザーに英語の文章が入力されたとき、文章はこのように単語に区切られたもの(単語列)を出力します(下図)。
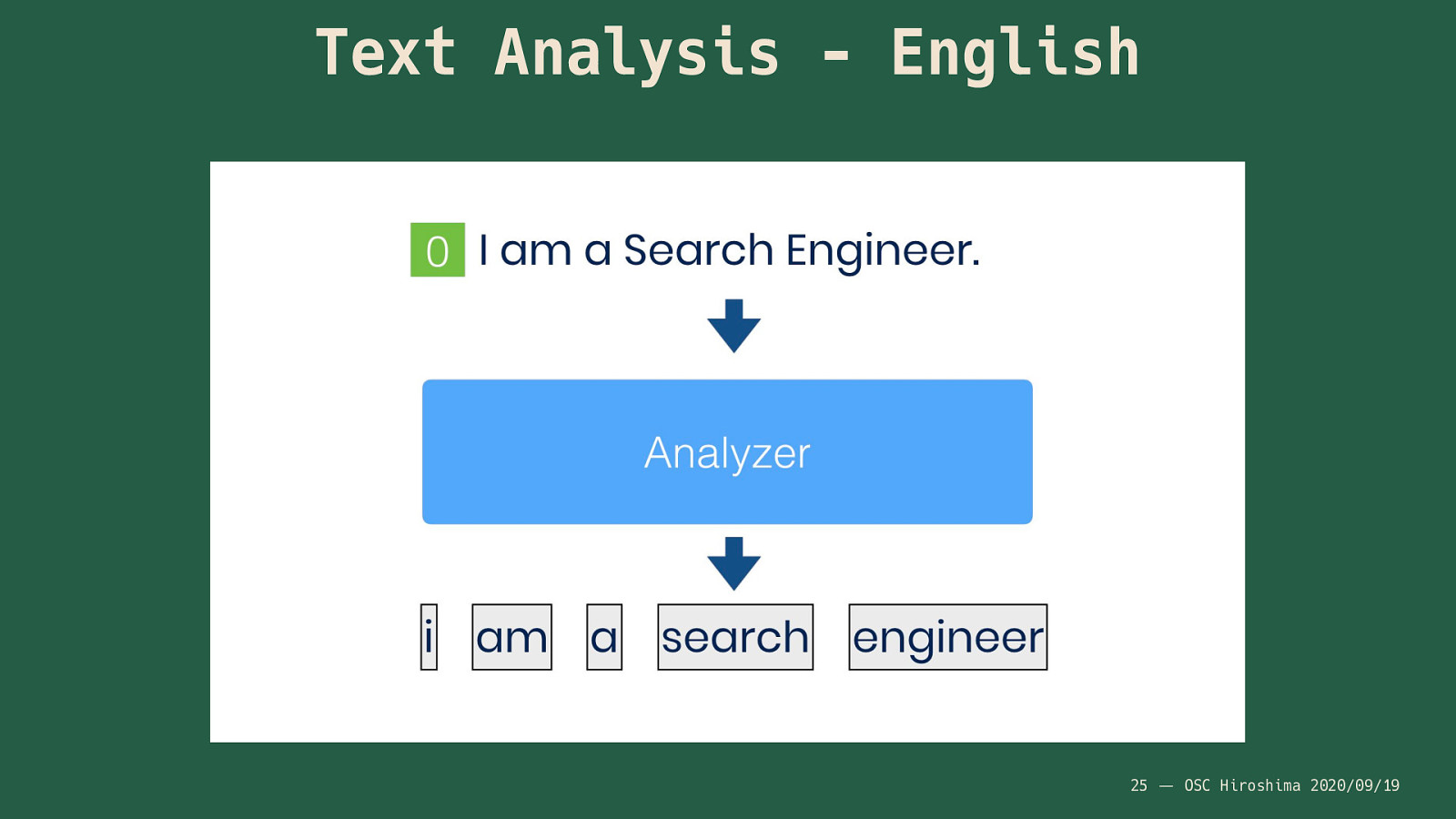
今回はNGramの話なので、NGramのAnalyzerを利用してみるとこんな感じになります。

実際に出来上がる転置インデックスは次のような形になります。

検索の仕組み(おさらい)
出来上がっている転置インデックスに対して検索をする場合、入力文字列(検索条件)に対して、転置インデックス作成時と同様にAnalyzerが動作します。 処理としては、
- クエリのパース
- フィールドのAnalyzerで処理
- 転置インデックスを検索
という形です。 例えばこんな感じ。
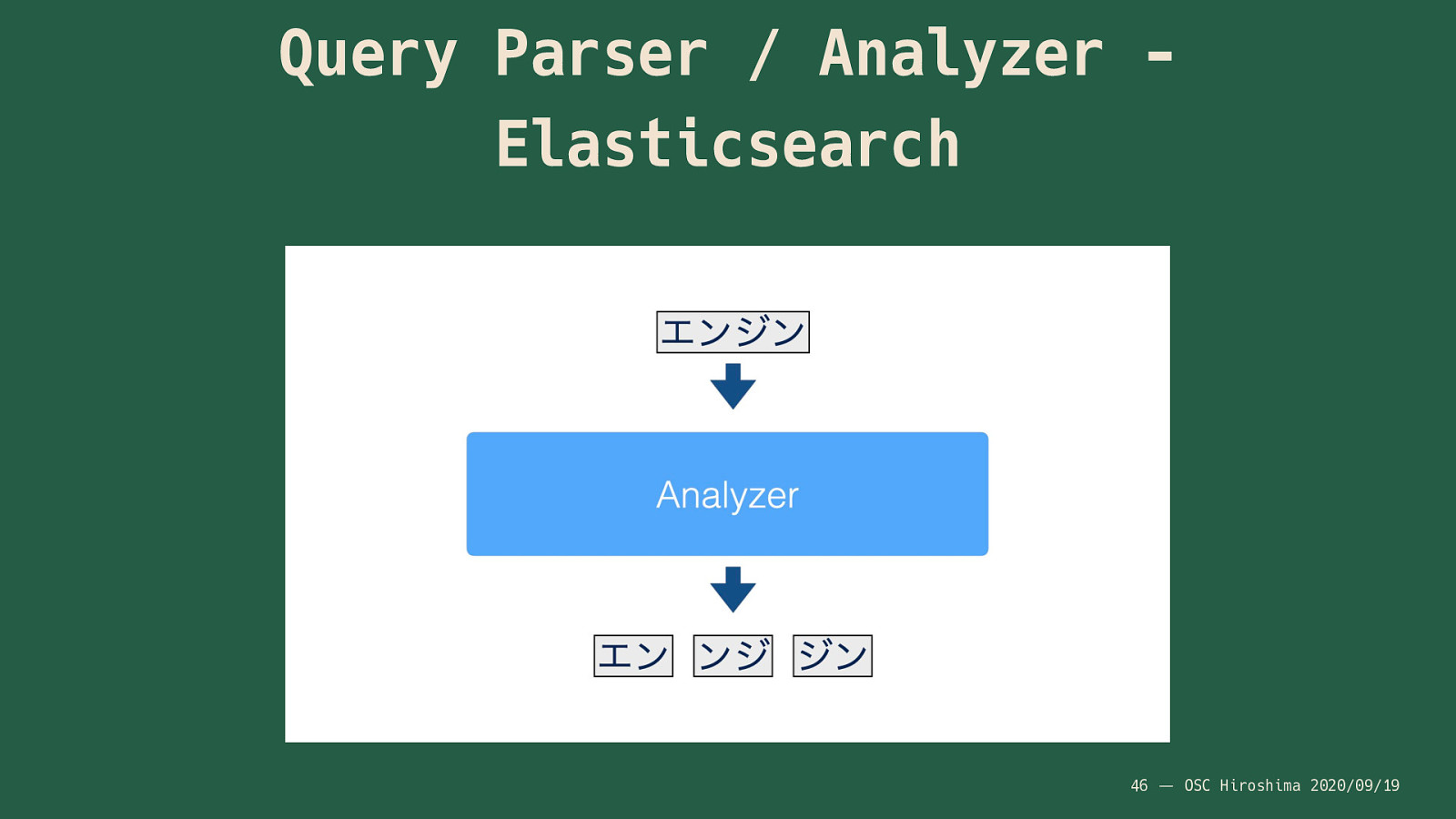
同じAnalyzerの処理が入ることで、転置インデックスに採用されているのと同じ単語が出てくるため、検索がきちんとできるということになります。
英語と日本語(NGram)の違い
英語と日本語の違いは、スペースの意味になります。 英語の場合は、スペースが単語の区切りになりますが、日本語の場合スペースでは区切られていません。
ですので、検索窓に入力された文字列は、英語の場合、クエリのパースの時点で単語に区切られます。そのあとにAnalyzerになるので、基本的には単語単位でAnalyzerの処理が動きます。そのあと、転置インデックスへの検索となります。なので、多くの場合はAnalyzerの出力は1単語です(類義語などを利用していたりする場合は異なりますが)。
日本語の場合、スペースでは区切られていないので、クエリのパースの時点で入力された文字列がそのままAnalyzerにわたります。 今回はAnalyzer(NGram)が単語に分割し、それをもとに検索処理が実行されます。
ismatchscoringの問題点は?(やっと帰ってきました)
さて、回り道をし、簡単ですが転置インデックスやAnalyzerについて説明しました。 では本題です。
$filter=search.ismatchscoring('ミルクティ')
このismatchscoring関数ですが、そのほかにも引数の指定が可能で、省略した場合にデフォルトで採用される値がいくつかあります。
公式のドキュメントにパラメータの意味が掲載されています。
今回は、第4引数のsearchModeの値が問題点です。デフォルトでは、anyが指定されます。
この、anyは検索語(今回はミルクティ)の任意の検索語句が一致する必要があることになります。
「検索語句」?なんでしょう?これが、ここまで回り道をして説明してきた、Analyzerの出力した単語になります。
「ミルクティ」はNGram(N=2)のAnalyzerを通すと、
「ミル」「ルク」「クテ」「ティ」
という4つの単語が出力されます。 これが、「検索語句」です。「任意の」とあるので、上記4つの2文字のどれか?が出現すれば検索条件にヒットしたこととなります。
ですので、以下のように(一部のみ色を変えてます)3つの文章にはそれぞれの文字が含まれているため、先ほどの条件では3件の結果が返ってくることになります。
ミルクティを飲みたいです。- マ
ティーニはカクテルですが、ミルクセーキは? - 風呂上がりの
ミルクは最高です。
NGramで一部分の単語だけで一致したものがヒットしてしまうと違和感があるので、allに変更します。
$filter=search.ismatchscoring('ミルクティ', 'body', 'simple', 'all')
今度はどうなるでしょう?
ミルクティを飲みたいです。- マ
ティーニはカクテルですが、ミルクセーキは?
先ほどよりもマシになりました。 3がヒットしなくなっています。3の文章には「ティ」などが出てこないためです。 ただ、感覚的に2番目がヒットするのは少し違和感がありますよね? 確かに4つの単語がすべて出てきていますが、「ミルクティ」とは少し遠いです。
さらに「ミルクティ」にヒットさせるにはフレーズ検索にする必要があります。 Elastic社のブログの日本語の検索に関する記事でも出てきますが、フレーズで検索することで「ミルクティ」だけにヒットさせることができます。
「フレーズ検索=語順を保証する検索」となります。 ですので、
「ミル」「ルク」「クテ」「ティ」
この順序で出てきた場合のみ、検索にヒットしたことになります。
OData式でフレーズ検索する場合は、単語をダブルクォート"でくくる必要があります(公式ドキュメントの例に記載あり)。
$filter=search.ismatchscoring('"ミルクティ"', 'body', 'simple', 'all')
これで結果は以下の1件だけとなります。
ミルクティを飲みたいです。
これでNGramで部分一致のような挙動で日本語の検索ができるようになりました。
ちなみに、フレーズにした場合は第4引数はanyに変更しても1件だけの検索結果となります。
フレーズ検索には「すべての語が含まれる」、「すべての語が順番に現れる」という2つの条件が含まれるためです。
$filter=search.ismatchscoring('"ミルクティ"', 'body', 'simple', 'any')
この例の引数をミルクティを"ミルク" "最高"のような検索条件に変えた場合、「“ミルク”」「“最高”」の2つの条件をanyで扱うため、
「“ミルク”」「“最高”」のどちらかが出てくれば良い結果となり、3件の結果が返ってきます。
第4引数をallに変更すると、「“ミルク”」「“最高”」の両方が出てこなければならないため、3件目のデータのみが返ってきます。
$filter=search.ismatchscoring('"ミルクティ" "最高"', 'body', 'simple', 'all')
これは、
$filter=search.ismatchscoring('"ミルクティ"', 'body', 'simple', 'any') and search.ismatchscoring('"最高"', 'body', 'simple', 'any')
と同じ意味となります。
少し長くはなりますが、後者の書き方をプログラムで書くと思います、私の場合は。
検索窓に入力された単語に必ず"を追加する処理を書くために、画面入力の文字列を一旦パースをすることになるからです。
まとめ
簡単?にですが、OData式でのフルテキスト検索と、NGramでのフレーズ検索について説明しました。 英語の場合、もともとスペースで区切られているので、フレーズといわれてピンときますが、日本語の場合はAnalyzerの挙動をわかっていないと「?」となるかと思います。 なぜフレーズ検索が必要なのか?というのが少しでもわかっていただければと。 ちなみに、NGramのTokenizerには別の落とし穴もありますが、その話はまた後日にでも。
参考として日本語関連の検索に関する記事のリンクを残しておきます。
参考
- Elasticsearch日本語でフレーズ検索が必要なわけ
- NGramも含め、Elasticsearchでの日本語の検索の設定やクエリについては、Elastic社のブログで日本語で書かれた記事が詳しいのでこちらをご覧いただくのがいいです。
comments powered by Disqus
See Also by Hugo
- Elasticsearchの新しいJavaクライアント(2024年3月版)
- ローマ字入力のゆれと読み(JapaneseCompletionAnalyzerその2)
- Elasticsearchの新しいJavaクライアント
- Index Template V2
- ElasticSearchにプラグインで日本語Wikipediaデータを入れてみました
